3 Organização dos dados: Tidy data
Nas ciências, a organização dos seus dados é tão importante quanto a análise em si. Um formato de dados bem estruturado facilita a manipulação, a análise e a visualização, tornando todo o processo mais eficiente e menos propenso a erros. É nesse contexto que entra o conceito de Tidy Data (Wickham (2014)).
As regras básicas são simples, mas poderosas:
Cada variável em uma coluna: As colunas do seu conjunto de dados devem representar variáveis distintas, como “espécie”, “altura” ou “temperatura”.
Cada observação em uma linha: Cada linha deve corresponder a uma observação individual, como uma medição, um indivíduo ou um evento.
Cada valor em uma célula: Cada célula na tabela deve conter um único valor, representando a interseção de uma variável e uma observação.
Uma função bastante útil para organizar os dados no fomato tidy é a função tidyr::pivot_longer1.
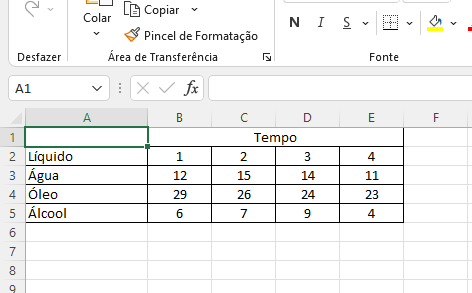
Considere o conjunto de dados presente nesta planilha do Excel: liquido.xlsx (Figura Figura 3.1)
Os dados foram digitados de modo que os valores da variável tempo estão espalhados por 4 colunas. A variável repetição (implícita) está em uma linha (cabeçalho das colunas) e o nome das colunas (Tempo) está em uma célula mesclada.
Ao importar este arquivo com a função readxl::read_excel temos como resultado:
messy_data <- readxl::read_excel("liquido.xlsx")
messy_dataNew names:
• `` -> `...1`
• `` -> `...3`
• `` -> `...4`
• `` -> `...5`# A tibble: 4 × 5
...1 Tempo ...3 ...4 ...5
<chr> <dbl> <dbl> <dbl> <dbl>
1 Líquido 1 2 3 4
2 Água 12 15 14 11
3 Óleo 29 26 24 23
4 Álcool 6 7 9 4Observamos que a primeira linha (células mescladas) da planilha bagunçou ainda mais o resultado. Vamos importar novamente excluindo a primeira linha com o argumento skip = 1.
messy_data <- readxl::read_xlsx("liquido.xlsx", skip = 1)
messy_data# A tibble: 3 × 5
Líquido `1` `2` `3` `4`
<chr> <dbl> <dbl> <dbl> <dbl>
1 Água 12 15 14 11
2 Óleo 29 26 24 23
3 Álcool 6 7 9 4Para transformar o data-frame no formato tidy, utilizamos a função tidyr::pivot_longer:
tidy_data <- tidyr::pivot_longer(messy_data, cols = 2:5, names_to = "rep", values_to = "tempo")
tidy_data# A tibble: 12 × 3
Líquido rep tempo
<chr> <chr> <dbl>
1 Água 1 12
2 Água 2 15
3 Água 3 14
4 Água 4 11
5 Óleo 1 29
6 Óleo 2 26
7 Óleo 3 24
8 Óleo 4 23
9 Álcool 1 6
10 Álcool 2 7
11 Álcool 3 9
12 Álcool 4 4cols: colunas a serem transformadas para o formato tidy;names_to: nome da nova coluna criada a partir das informações armazenadas originalmente nos cabeçalhos das colunas;values_to: nome da nova coluna criada a partir dos valores armazenados nas células.
O caminho inverso também pode ser feito, transformando um data-frame do formato longo para o formato wide com a função tidyr::pivot_wider
Wickham, Hadley. 2014. “Tidy data”. The Journal of Statistical Software 59. http://www.jstatsoft.org/v59/i10/.
O formato Tidy Data também é conhecido como Formato Longo.↩︎