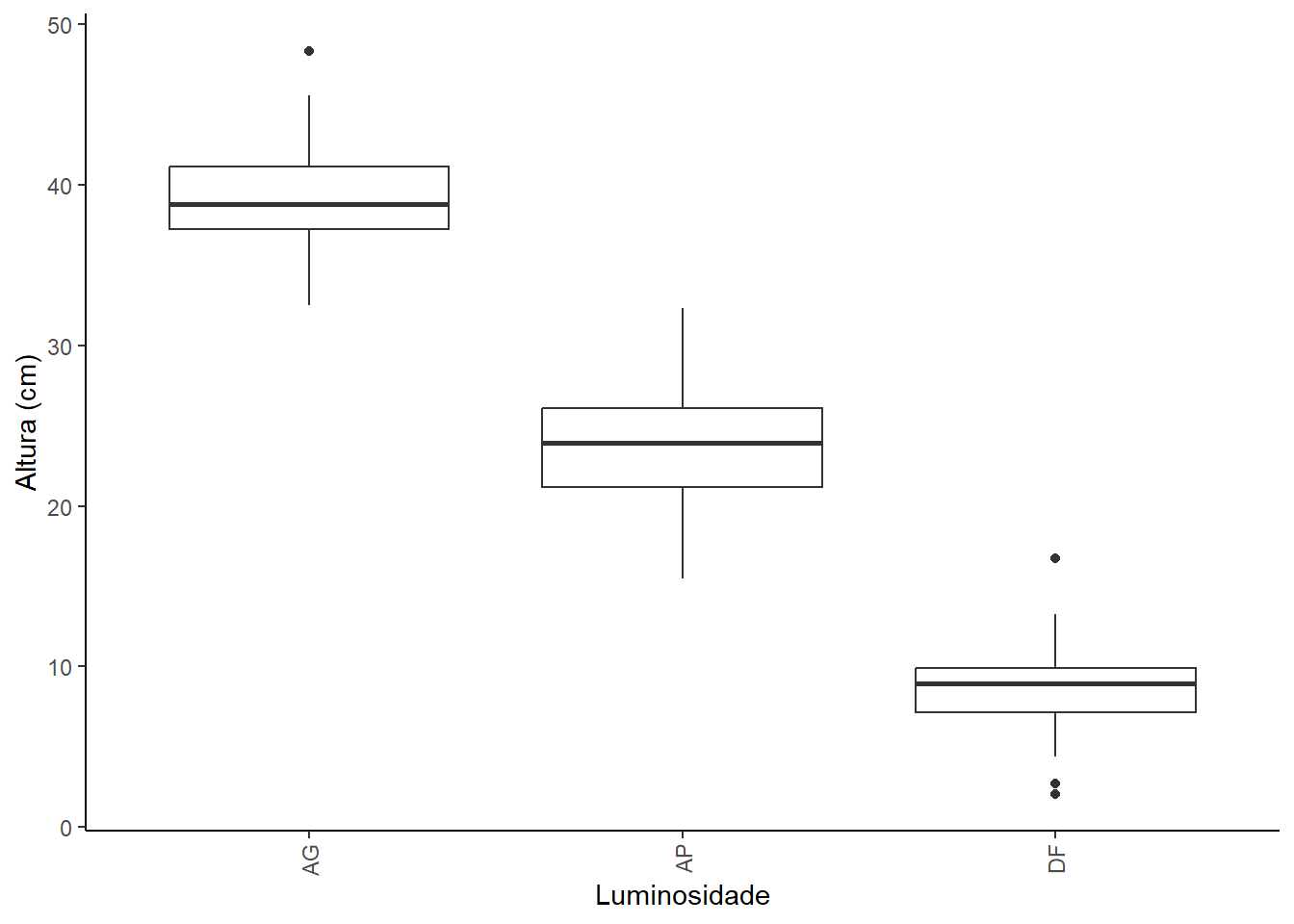17Análise de Variância para 2 fatores (Two-Way ANOVA)
A Análise de Variância para 2 fatores, também conhecida como ANOVA de dois fatores (Two-Way ANOVA) é um método estatístico empregado quando se deseja investigar como duas variáveis independentes, ou fatores, influenciam uma variável resposta.
A ANOVA de dois fatores é particularmente útil em estudos ou experimentos desenhados para responder a questões mais complexas do que aquelas que uma ANOVA para 1 fator consegue abranger. É comum, por exemplo, a necessidade de comparar tratamentos que são, na verdade, combinações de níveis de dois fatores distintos.
As principais questões que uma ANOVA de dois fatores busca responder são:
Existe um efeito principal do primeiro fator sobre a variável resposta?
Existe um efeito principal do segundo fator sobre a variável resposta?
Existe uma interação entre os dois fatores? Ou seja, o efeito de um fator sobre a variável resposta depende do nível do outro fator?
A inferência estatística em uma ANOVA de dois fatores envolve os seguintes passos:
Análise gráfica das médias dos grupos: Visualizar as médias da variável resposta para cada combinação dos níveis dos fatores.
Procurar por indicações visuais de interação entre os fatores.
Procurar por indicações visuais de efeitos principais de cada fator.
Teste F: Realizar testes de hipóteses para avaliar formalmente:
A significância da interação entre os dois fatores.
A significância do efeito principal do primeiro fator.
A significância do efeito principal do segundo fator.
Ao longo deste capítulo, serão apresentados exemplos práticos que ilustram diversas situações encontradas na aplicação da ANOVA de 2 fatores.
17.1 Análise de Variância para dois fatores - interação não significativa.
Esta seção é dedicada à Análise de Variância (ANOVA) de dois fatores para situações em que a interação entre esses dois fatores não se revela estatisticamente significativa. O exemplo a seguir demonstrará como conduzir e interpretar uma ANOVA de dois fatores neste cenário específico.
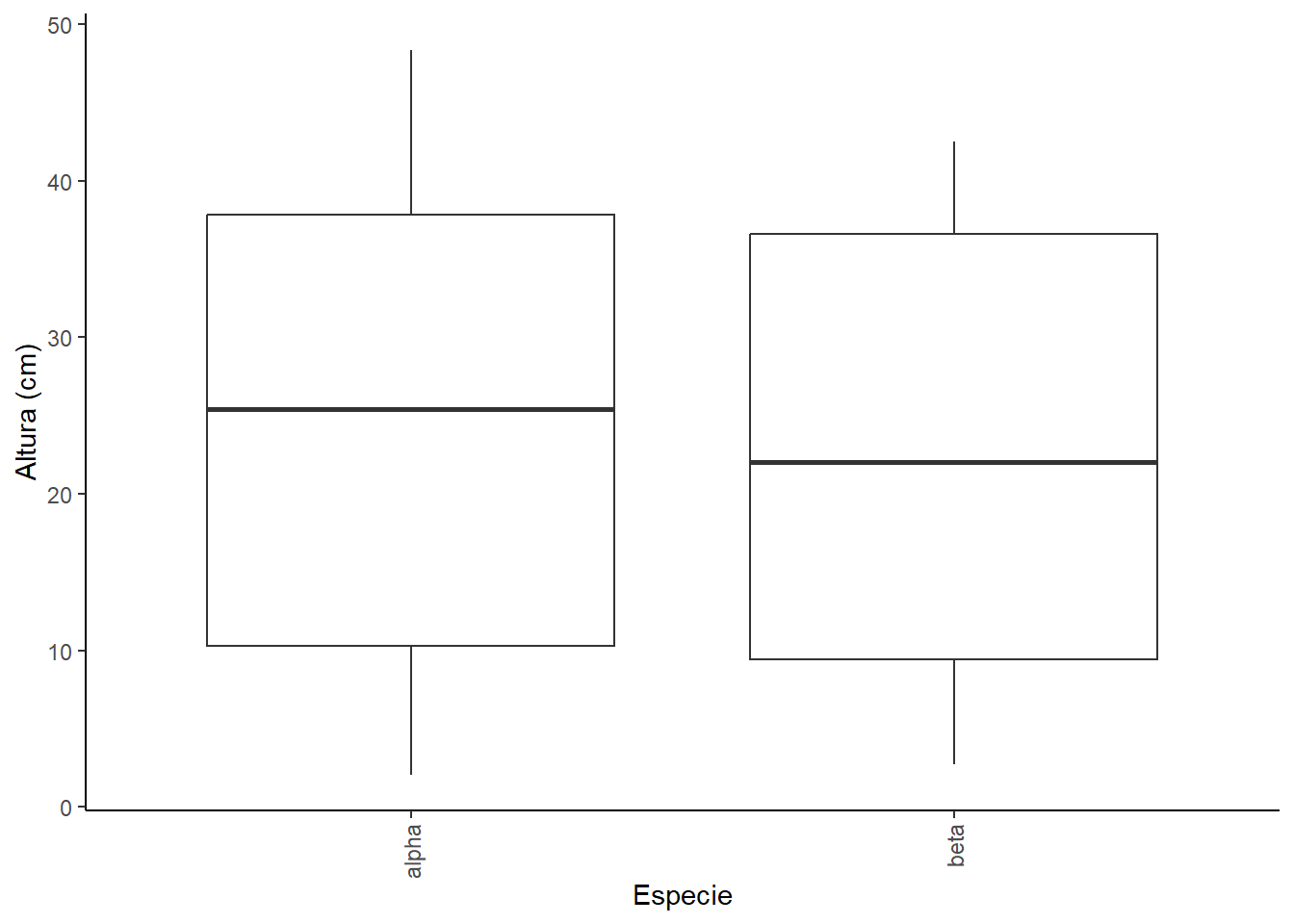
Exemplo 17.1 (Análise de Variância para dois fatores - interação não significativa.) A restauração de ecossistemas florestais busca otimizar o crescimento de mudas. A quantidade de luz que atinge o sub-bosque e a escolha da espécie arbórea podem ser determinantes para o sucesso inicial do estabelecimento. Um experimento foi conduzido para avaliar o crescimento em altura de mudas de duas espécies arbóreas nativas sob diferentes condições de luminosidade simuladas por aberturas de dossel. Foram testados três níveis de luminosidade (Fator A): Dossel Fechado (DF), Abertura Pequena (AP) e Abertura Grande (AG). Duas espécies de árvores (Fator B) foram utilizadas: Espécie Alfa (uma espécie pioneira de crescimento rápido) e Espécie Beta (uma espécie clímax tolerante à sombra). O experimento utilizou 15 mudas por combinação de tratamento, totalizando 90 mudas. A resposta foi o crescimento em altura (cm) das mudas após um período de 12 meses, com dados contidos no arquivo mudas.csv.
São três grupos de hipóteses a serem testadas:
Interação:
H0: não há interação entre o nível de luminosidade e a espécie arbórea no crescimento em altura das mudas.
H1: há interação entre o nível de luminosidade e a espécie arbórea no crescimento em altura das mudas.
Efeito principal da luminosidade:
H0: o nível de luminosidade não influencia o crescimento em altura das mudas.
H1: o nível de luminosidade influencia o crescimento em altura das mudas.
Efeito principal da espécie:
H0: a espécie arbórea não influencia o crescimento em altura das mudas.
H1: a espécie arbórea influencia o crescimento em altura das mudas.
Análise exploratória:
mudas <- readr::read_csv("mudas.csv") # importar os dados
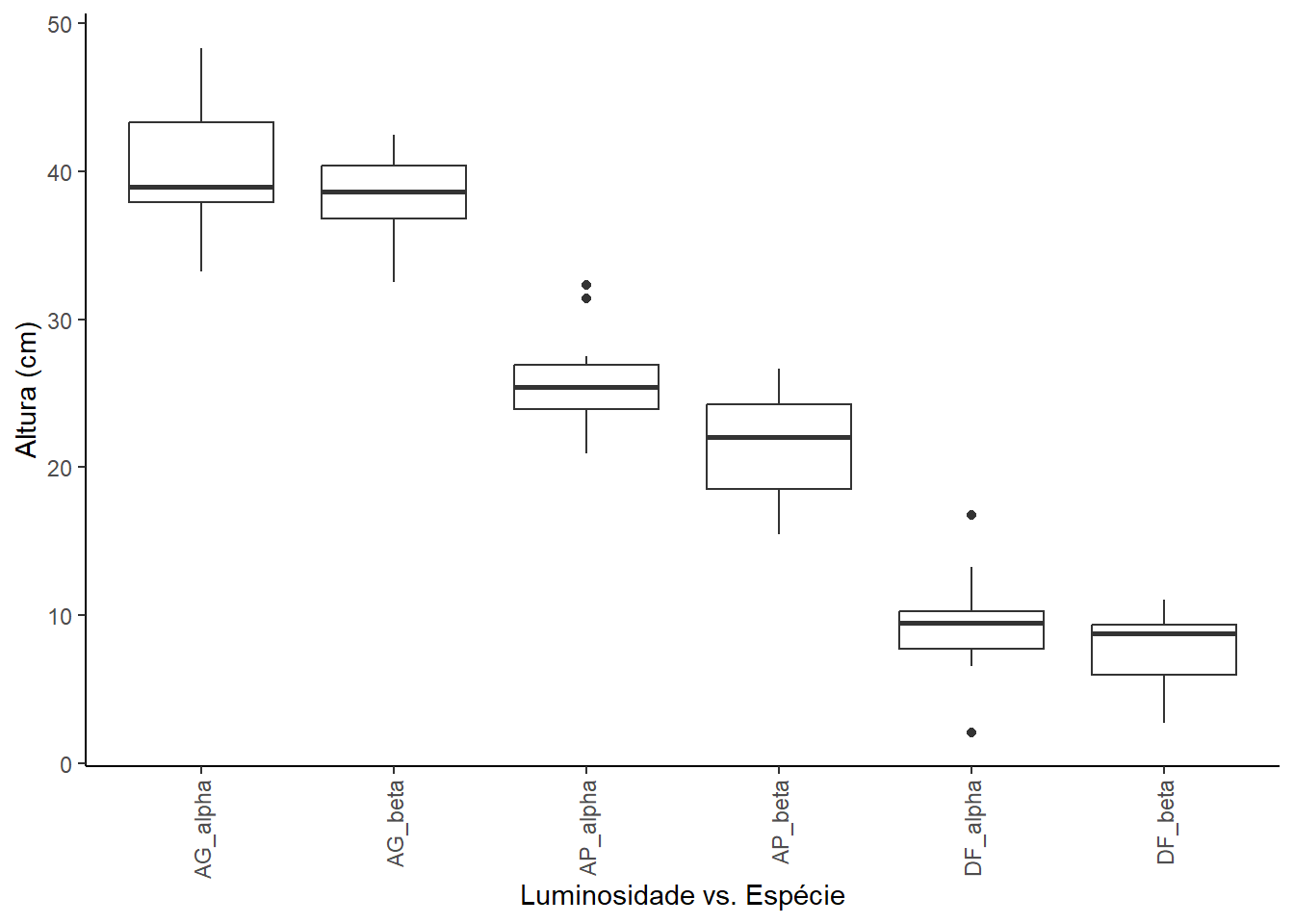
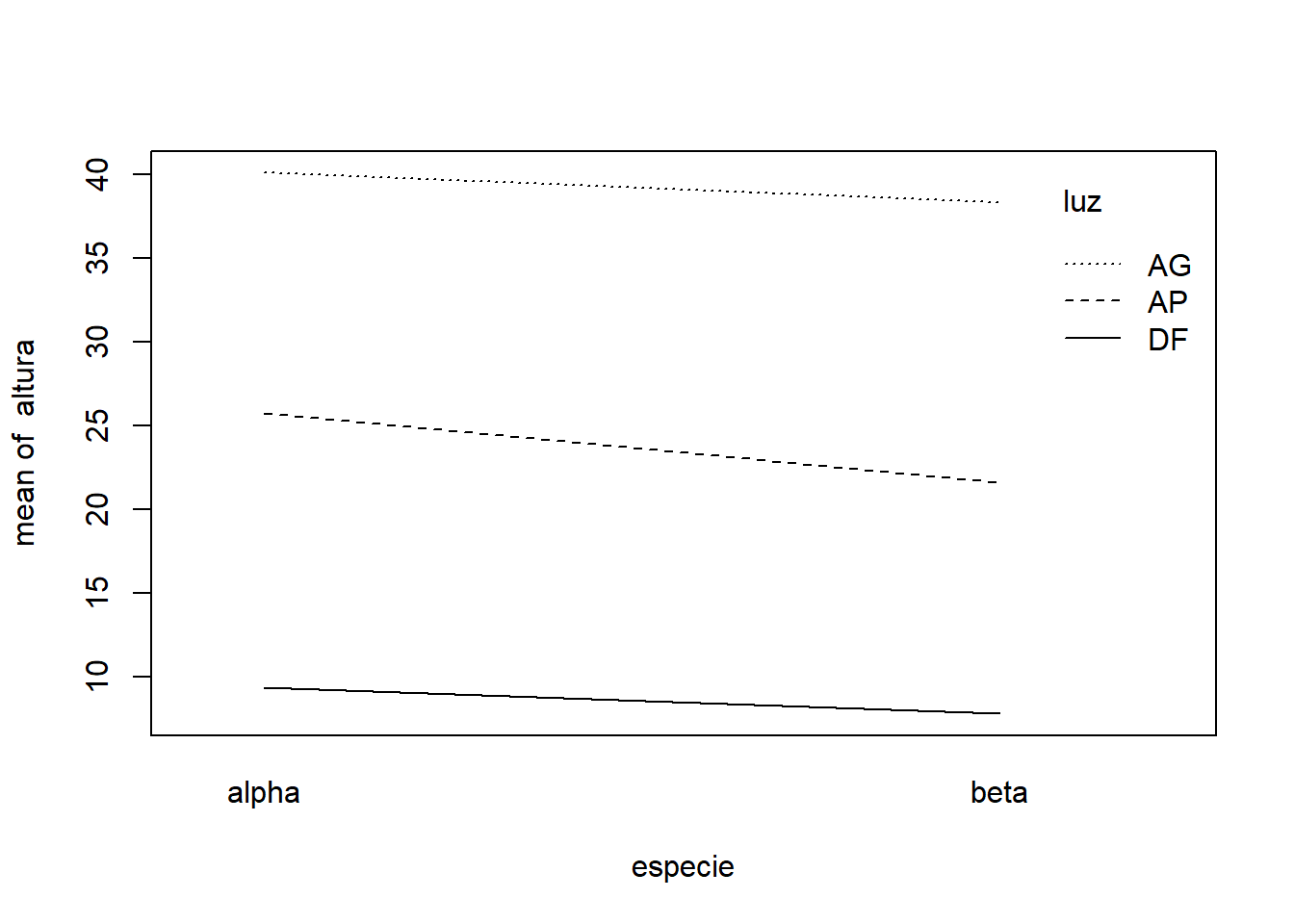
A análise exploratória mostra que a altura média das mudas varia consideravelmente com o nível de luminosidade, sendo maior para AG e Ap e menor para DF. Para o fator espécie, a espécie alpha apresenta uma altura média ligeiramente superior à da espécie beta. Os boxplots comparativos do fatorial mostram um padrão: dentro de cada nível de luminosidade, a espécie “alpha” tende a ser um pouco mais alta que a “beta”. Além disso, para ambas as espécies, o aumento da luminosidade leva a um aumento na altura.
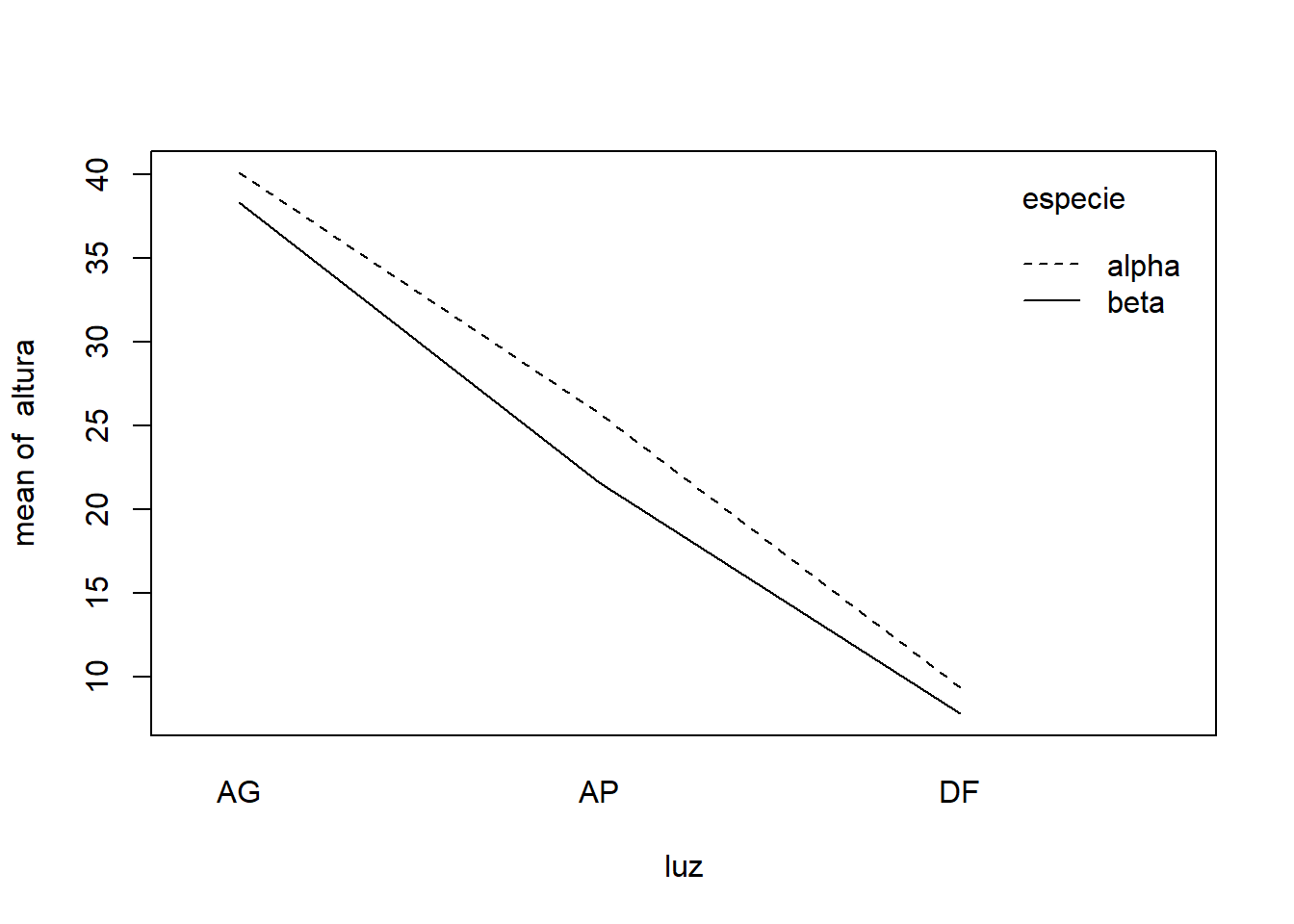
O gráfico da interação luz vs especie mostra um comportamento bastante similar à medida que o nível de luminosidade muda. Ambas as linhas sobem de DF para AP e de AP para AG, indicando que maior luminosidade aumenta a altura média para ambas as espécies. As linhas parecem ser aproximadamente paralelas, o que sugere visualmente que o efeito da luminosidade sobre a altura não difere muito entre as duas espécies, ou seja, não há uma interação forte aparente.
Já o gráfico da interação especie vs luz mostra as linhas aproximadamente paralelas quando comparamos a espécie “alpha” com a “beta”. A linha para AG está consistentemente acima da linha para AP, que por sua vez está acima da linha para DF, para ambas as espécies. A diferença de altura entre os níveis de luminosidade parece ser similar para a espécie “alpha” e para a espécie “beta”. Isso reforça a sugestão visual de ausência de interação significativa.
Ambos os gráficos de interação sugerem que não há uma interação forte ou óbvia entre o nível de luminosidade e a espécie arbórea no que diz respeito à altura média das mudas.
Executando a Análise de Variância (ANOVA):
Procedemos com o teste F da ANOVA:
aov_mudas <-lm(altura ~ luz * especie, data = mudas)anova(aov_mudas)
term
df
sumsq
meansq
statistic
p.value
luz
2
14.108,33
7.054,16
636,04
<0.001 *
especie
1
138,81
138,81
12,52
<0.001 *
luz:especie
2
30,19
15,09
1,36
0.262
Residuals
84
931,62
11,09
*Estatisticamente significativo (nível de 5%)
Conclusão da ANOVA:
A análise de variância revelou que a interação entre o nível de luminosidade e a espécie arbórea não foi estatisticamente significativa (p-valor = 0,262) no que tange ao crescimento em altura das mudas. Essa ausência de significância estatística para a interação corrobora a observação visual dos gráficos de interação, onde as linhas que representam os efeitos de um fator se mantêm aproximadamente paralelas ao longo dos níveis do outro fator. Isso significa que o efeito de diferentes níveis de luminosidade sobre a altura das mudas é consistente para ambas as espécies (Alfa e Beta), e, similarmente, a diferença de altura entre as espécies Alfa e Beta se mantém relativamente constante independentemente do nível de luminosidade.
No entanto, foram encontrados efeitos principais significativos para ambos os fatores. O nível de luminosidade teve um impacto altamente significativo no crescimento em altura das mudas (p-valor <0,001). Da mesma forma, a espécie arbórea também apresentou um efeito principal significativo sobre a altura (p-valor <0,001)
Embora tanto a luminosidade quanto a espécie da muda afetem o crescimento em altura, a magnitude do efeito da luminosidade não depende da espécie, e a diferença entre as espécies não é alterada pelos diferentes níveis de luminosidade testados.
17.1.1 Testes post-hoc para anova de 2 fatores - interação não significativa.
Quando a análise de variância (ANOVA) de dois fatores indica que não há uma interação estatisticamente significativa entre os dois fatores, isso significa que o efeito de um fator sobre a variável resposta é consistente em todos os níveis do outro fator. Em outras palavras, os fatores não se influenciam mutuamente de maneira complexa para alterar o resultado.
Nesse cenário, a interpretação dos resultados se torna mais direta. Os testes post-hoc, que são utilizados para identificar exatamente quais médias de grupos são diferentes entre si após um resultado significativo na ANOVA, são aplicados individualmente aos efeitos principais de cada fator. Essencialmente, cada fator é examinado separadamente, como se você estivesse realizando uma análise post-hoc para estudos de um único fator. Isso ocorre porque a ausência de interação sugere que o impacto de um fator não depende do nível específico do outro fator.
Exemplo 17.2 (Testes post-hoc - interação não significativa.) .
Teste de Tukey para o efeito principal da luminosidade:
# Carregar pacotes se ainda não estiverem carregadospacman::p_load("emmeans", "multcomp", "multcompView")# Calcular as médias marginais estimadas e aplicar o teste de Tukeytk_luz <- emmeans::emmeans(aov_mudas, ~luz, contr ="tukey")
NOTE: Results may be misleading due to involvement in interactions
# Contrastes (comparações par a par)tk_luz$contrasts
contrast estimate SE df t.ratio p.value
AG - AP 15,6 0,86 84 18,099 0,0000
AG - DF 30,7 0,86 84 35,665 0,0000
AP - DF 15,1 0,86 84 17,566 0,0000
Results are averaged over the levels of: especie
P value adjustment: tukey method for comparing a family of 3 estimates
# Intervalos de confiança para os contrastestk_luz$contrasts |>confint()
contrast estimate SE df lower.CL upper.CL
AG - AP 15,6 0,86 84 13,5 17,6
AG - DF 30,7 0,86 84 28,6 32,7
AP - DF 15,1 0,86 84 13,1 17,2
Results are averaged over the levels of: especie
Confidence level used: 0,95
Conf-level adjustment: tukey method for comparing a family of 3 estimates
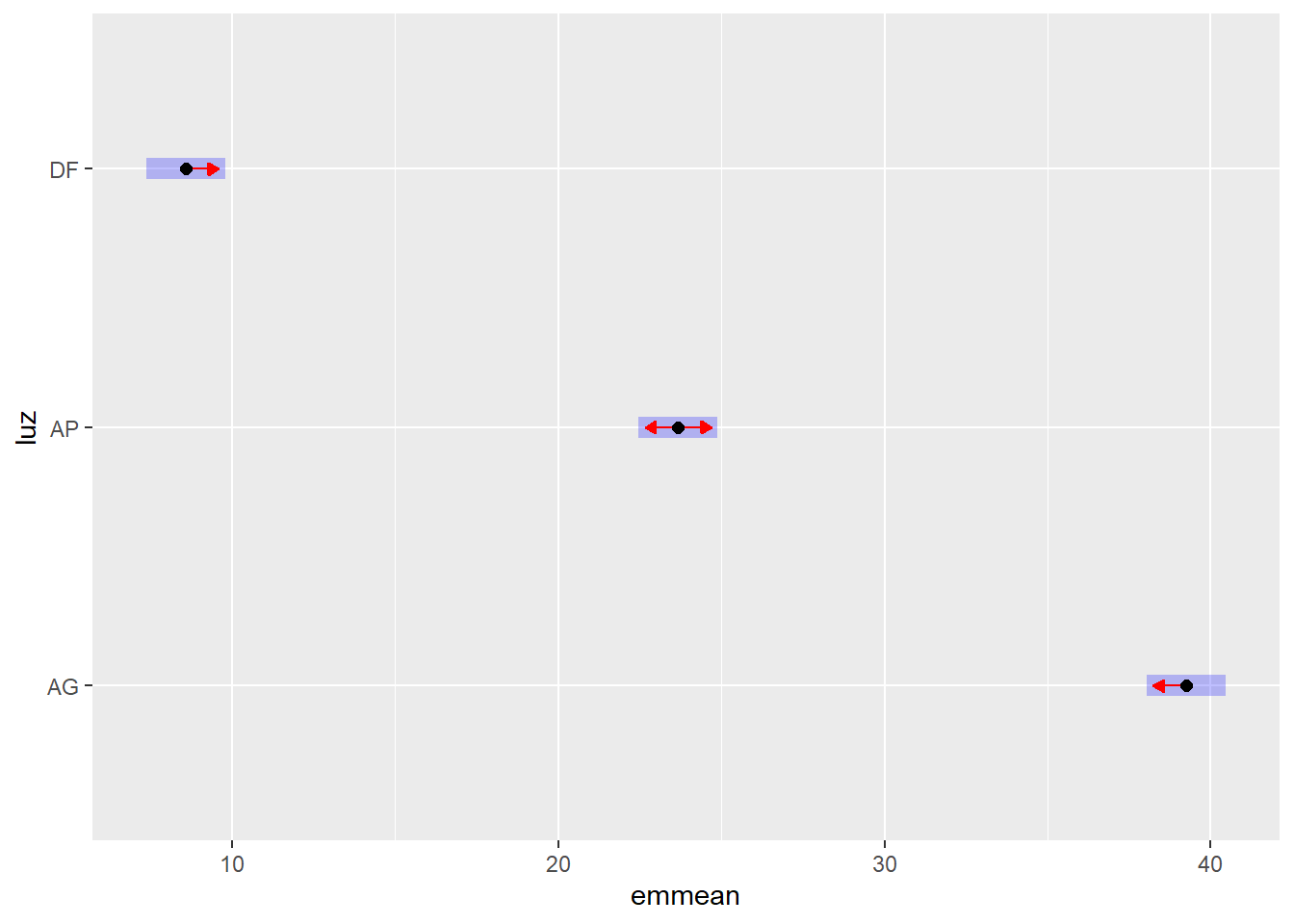
# Médias marginais estimadas e Compact Letter Display (CLD)## Ajustar 'Letters = letters' ou 'Letters = LETTERS' para minúsculas ou maiúsculas## Ajustar decreasing = TRUE para letras decrescentes e decreasing = FALSE para crescentestk_luz$emmeans |> multcomp::cld(Letters = letters, decreasing =TRUE)
luz emmean SE df lower.CL upper.CL .group
AG 39,25 0,608 84 38,04 40,45 a
AP 23,68 0,608 84 22,47 24,89 b
DF 8,58 0,608 84 7,37 9,79 c
Results are averaged over the levels of: especie
Confidence level used: 0,95
P value adjustment: tukey method for comparing a family of 3 estimates
significance level used: alpha = 0,05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
# Gráfico das médias com intervalo de confiançatk_luz$emmeans |>plot(comparisons =TRUE, CIs =TRUE)
Tabela X. Médias de altura das mudas (cm) submetidas a diferentes regimes de luminosidade.
Luminosidade
Altura (cm)
AG
39,25 a
AP
23,68 b
DF
8,58 c
Médias com a mesma letra não diferem significativamente (teste de Tukey, 0%)
De acordo com o teste de Tukey (com nível de significância de 5%), todos os níveis de luminosidade resultaram em alturas médias estatisticamente diferentes entre si. Especificamente:
As mudas sob Abertura Grande (AG) apresentaram a maior altura média.
Aquelas sob Abertura Pequena (AP) tiveram uma altura média intermediária.
As mudas em Dossel Fechado (DF) registraram a menor altura média.
Portanto, o aumento da luminosidade (de DF para AP, e de AP para AG) levou a um aumento progressivo e significativo na altura média das mudas.
Teste de Tukey para o efeito principal da espécie:
# Carregar pacotes se ainda não estiverem carregadospacman::p_load("emmeans", "multcomp", "multcompView")# Calcular as médias marginais estimadas e aplicar o teste de Tukeytk_especie <- emmeans::emmeans(aov_mudas, ~especie, contr ="tukey")
NOTE: Results may be misleading due to involvement in interactions
# Contrastes (comparações par a par)tk_especie$contrasts
contrast estimate SE df t.ratio p.value
alpha - beta 2,48 0,702 84 3,538 0,0007
Results are averaged over the levels of: luz
# Intervalos de confiança para os contrastestk_especie$contrasts |>confint()
contrast estimate SE df lower.CL upper.CL
alpha - beta 2,48 0,702 84 1,09 3,88
Results are averaged over the levels of: luz
Confidence level used: 0,95
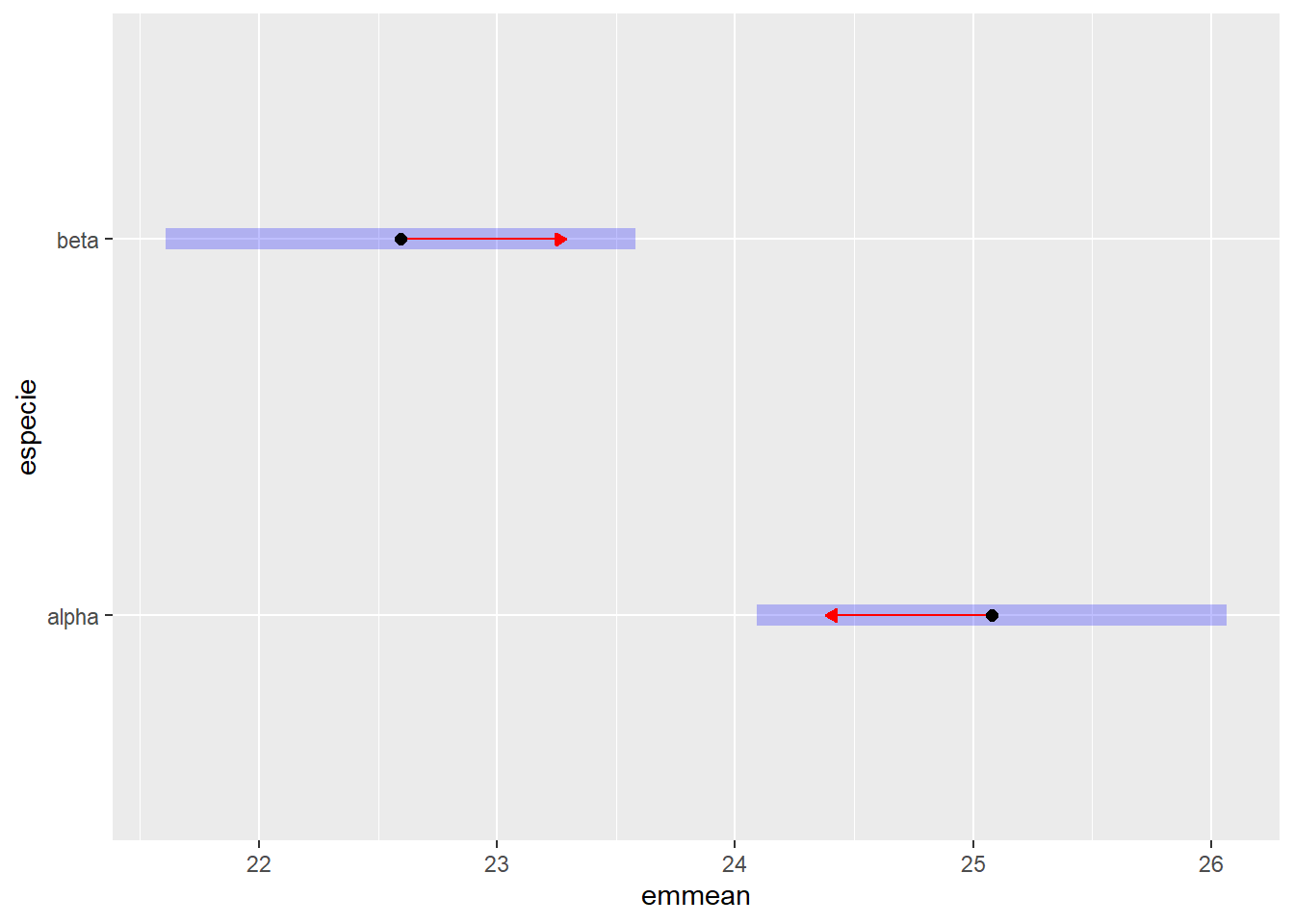
# Médias marginais estimadas e Compact Letter Display (CLD)## Ajustar 'Letters = letters' ou 'Letters = LETTERS' para minúsculas ou maiúsculas## Ajustar decreasing = TRUE para letras decrescentes e decreasing = FALSE para crescentestk_especie$emmeans |> multcomp::cld(Letters = letters, decreasing =TRUE)
especie emmean SE df lower.CL upper.CL .group
alpha 25,1 0,496 84 24,1 26,1 a
beta 22,6 0,496 84 21,6 23,6 b
Results are averaged over the levels of: luz
Confidence level used: 0,95
significance level used: alpha = 0,05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
# Gráfico das médias com intervalo de confiançatk_especie$emmeans |>plot(comparisons =TRUE, CIs =TRUE)
Tabela X. Médias de altura das mudas (cm) em diferentes espécies arbóreas.
Espécie
Altura (cm)
alpha
25,08 a
beta
22,59 b
Médias com a mesma letra não diferem significativamente (teste de Tukey, 0%)
De acordo com o teste de Tukey (com nível de significância de 5%), houve uma diferença estatisticamente significativa na altura entre as duas espécies. Conclui-se que a espécie Alfa teve um crescimento em altura significativamente maior que a espécie Beta nas condições avaliadas.
17.2 Análise de Variância para dois fatores - interação significativa com efeitos principais dominantes.
Nesta seção, o foco recai sobre a Análise de Variância (ANOVA) de dois fatores em cenários onde, apesar de uma interação estatisticamente significativa ser identificada entre os fatores, os efeitos principais de um ou de ambos os fatores são tão pronunciados e claros — ou seja, dominantes — que ainda fornecem conclusões gerais valiosas e diretas.
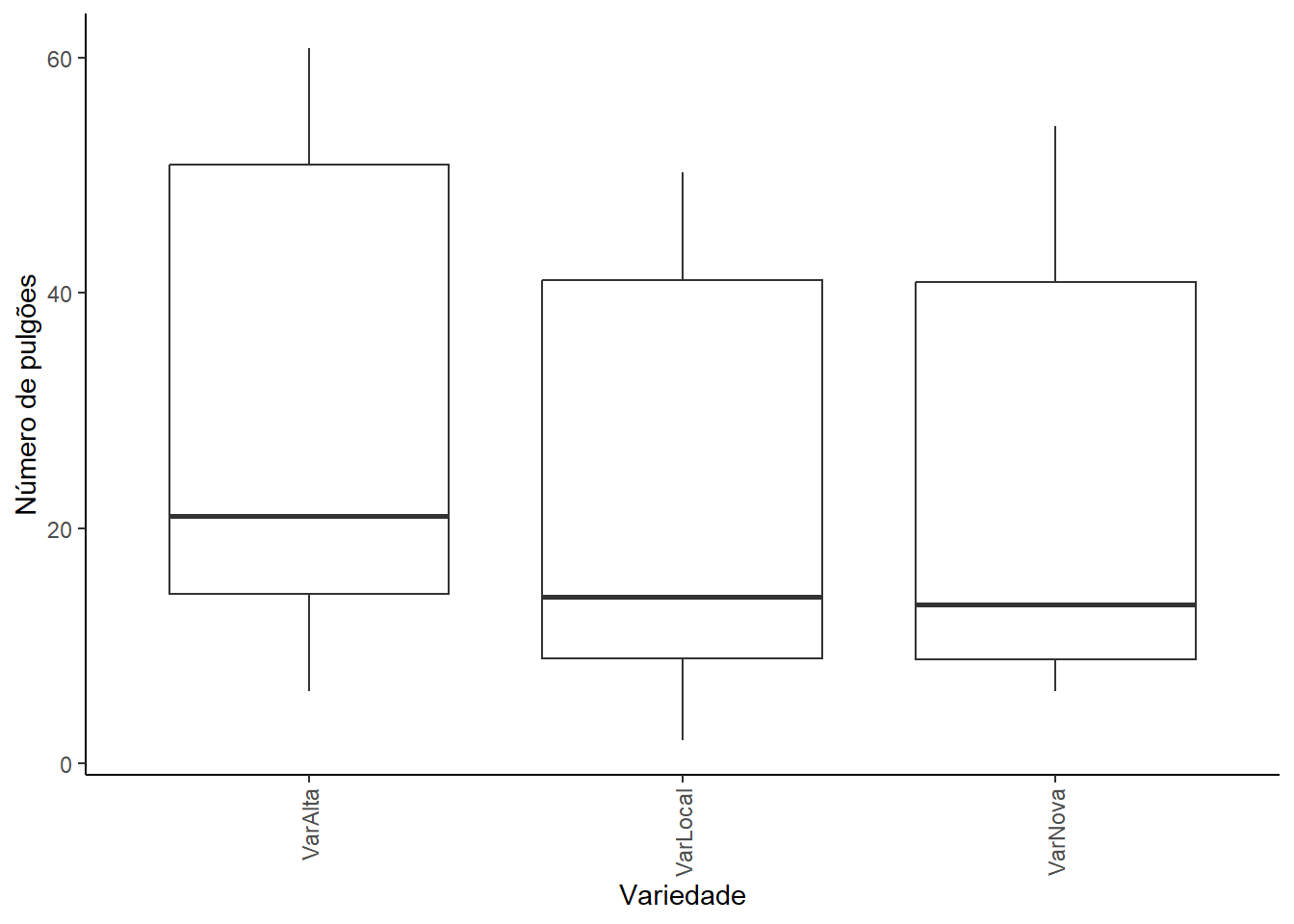
Exemplo 17.3 (Análise de Variância para dois fatores - interação significativa com efeitos principais dominantes.) A eficácia de agentes de controle biológico no manejo de pragas agrícolas pode variar dependendo da praga alvo e também da variedade da cultura hospedeira, que pode apresentar diferentes níveis de resistência natural ou ser mais ou menos atrativa para os agentes. Um estudo foi conduzido para avaliar a eficácia de inimigos naturais (Fator A) no controle de uma população de pulgões em variedades de pimentão (Fator B). Os tratamentos com inimigos naturais foram: JOA (um tipo de joaninha predadora), VES (uma vespa parasitoide) e TES (sem introdução de inimigos naturais). As variedades de pimentão testadas foram: VarAlta (uma variedade comercial de alta produtividade), VarLocal (uma variedade local, conhecida por sua rusticidade) e VarNova (uma nova variedade promissora em testes). O experimento foi conduzido em 4 blocos, resultando em 3 (agentes) x 3 (variedades) = 9 grupos de tratamento x 4 blocos, totalizando 36 unidades experimentais. A variável resposta foi o número médio de pulgões por folha, avaliado 15 dias após a introdução dos inimigos naturais (ou início do período de controle para o grupo sem agentes). Os dados estão no arquivo pulgao.csv.
São três grupos de hipóteses a serem testadas:
Interação:
H0: não há interação entre o tipo de inimigo natural e a variedade de pimentão no número médio de pulgões por folha.
H1: há interação entre o tipo de inimigo natural e a variedade de pimentão no número médio de pulgões por folha.
Efeito principal do inimigo natural:
H0: o tipo de inimigo natural (incluindo controle) não influencia o número médio de pulgões por folha.
H0: o tipo de inimigo natural (incluindo controle) influencia o número médio de pulgões por folha.
Efeito principal da espécie:
H0: a variedade de pimentão não influencia o número médio de pulgões por folha.
H1: a variedade de pimentão influencia o número médio de pulgões por folha.
Análise exploratória:
pulgao <- readr::read_csv("pulgao.csv") # importar os dados
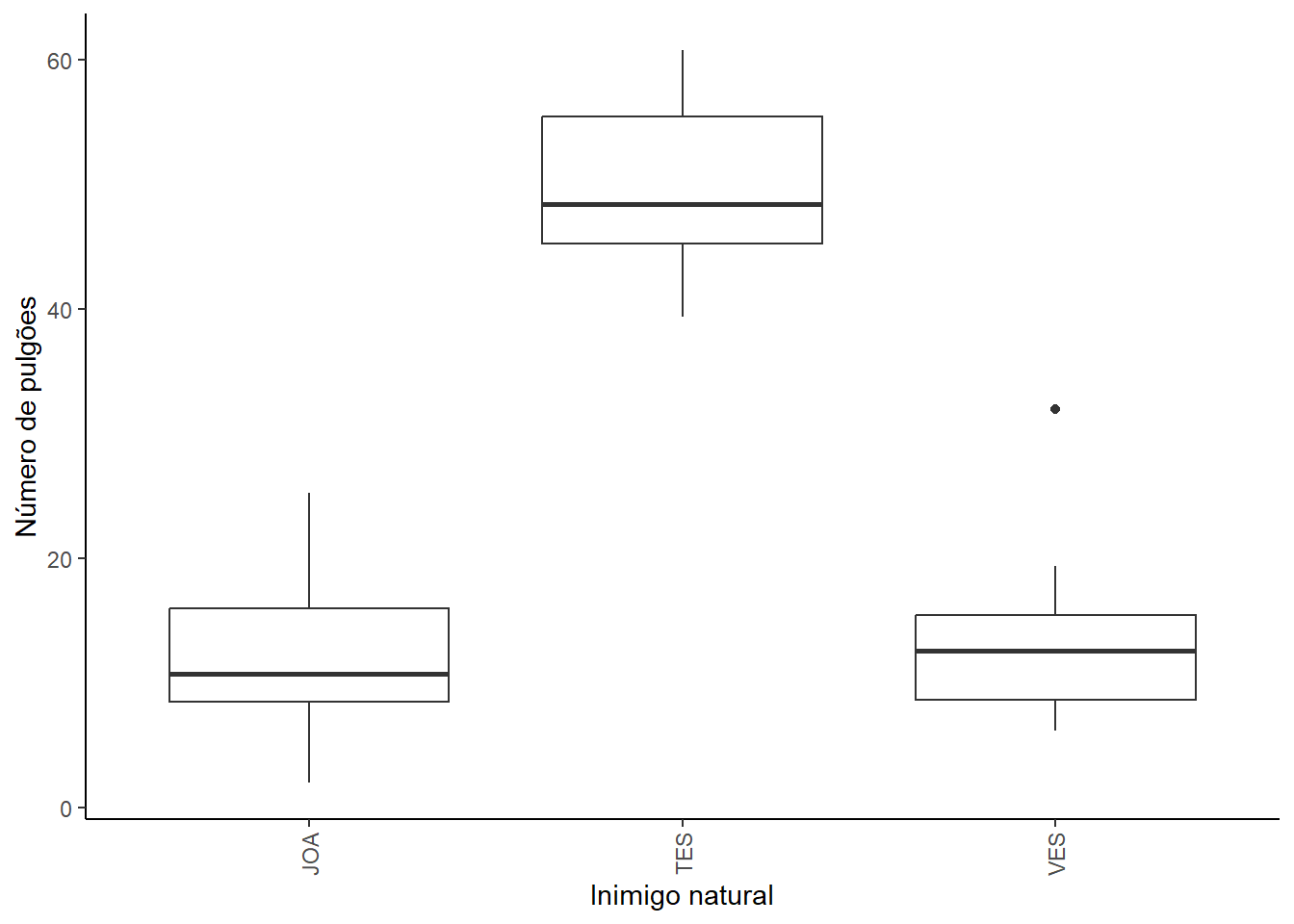
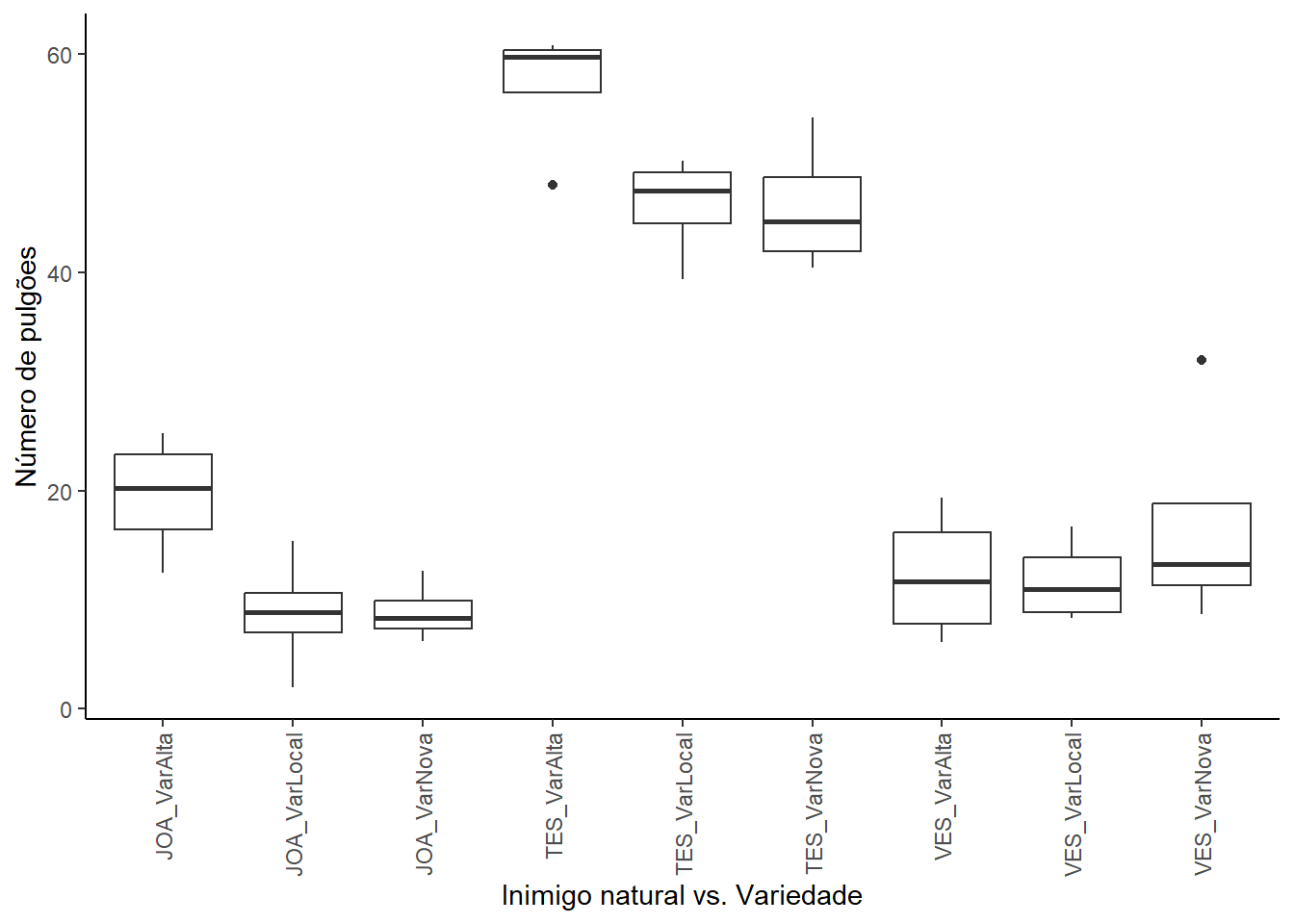
pulgao |>ggplot(aes(x = fatorial, y = numero)) +geom_boxplot() +labs(x ="Inimigo natural vs. Variedade",y ="Número de pulgões" ) +theme_classic()+theme(axis.text.x =element_text(angle =90, hjust =1, vjust =0.5))
O tratamento Testemunha apresenta a maior média de pulgões, enquanto Joaninha e Vespa apresentam médias consideravelmente mais baixas. A variedade Alta tem a maior média de pulgões, seguida pela variedade Nova e pela variedade Local.
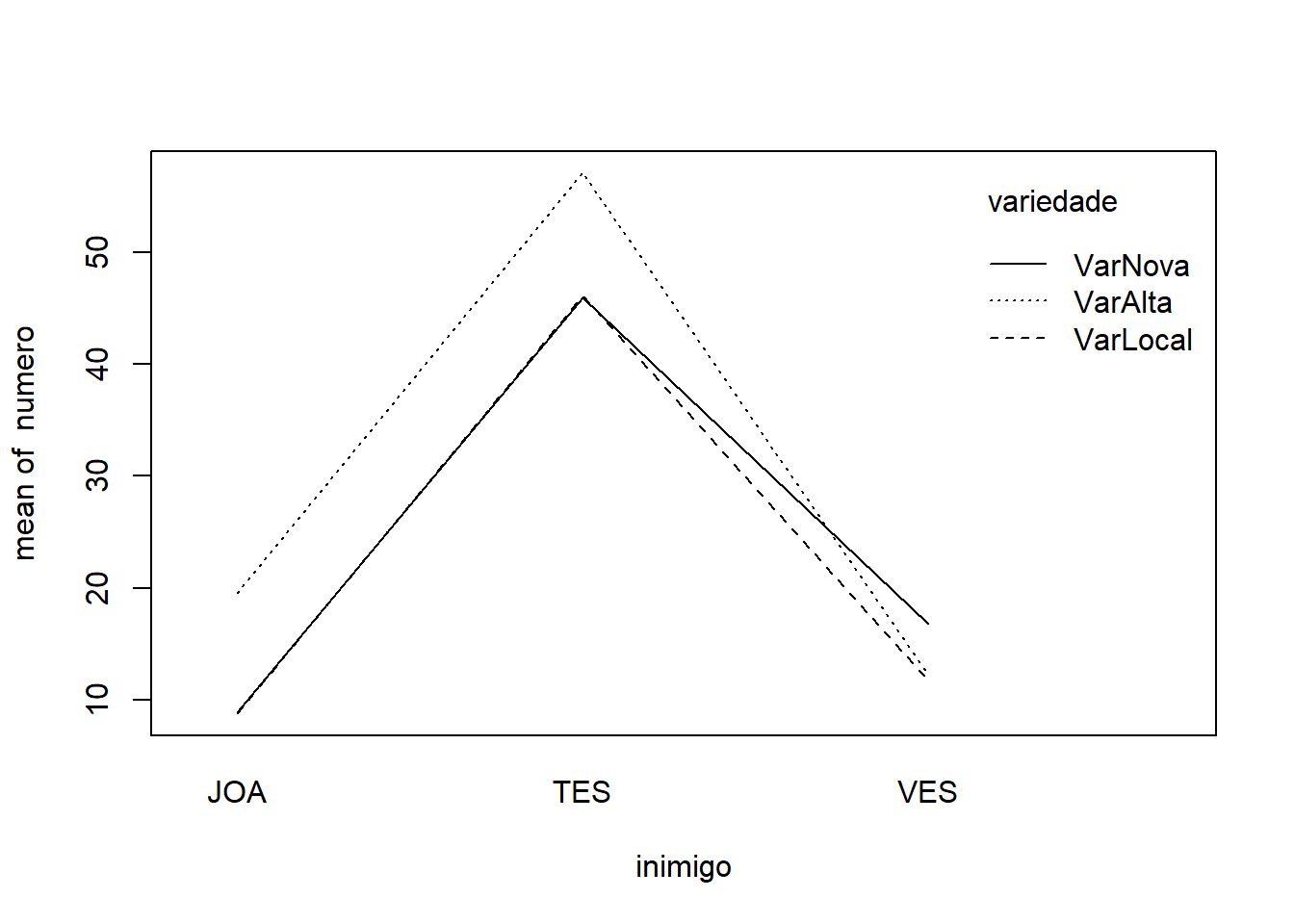
O gráfico da interação inimigo vs variedade mostra linhas não paralelas. Todas as variedades mostram um pico de infestação com o tratamento testemunha. No entanto, a magnitude desse pico e os níveis de infestação com joaninha e vespa variam entre as variedades.
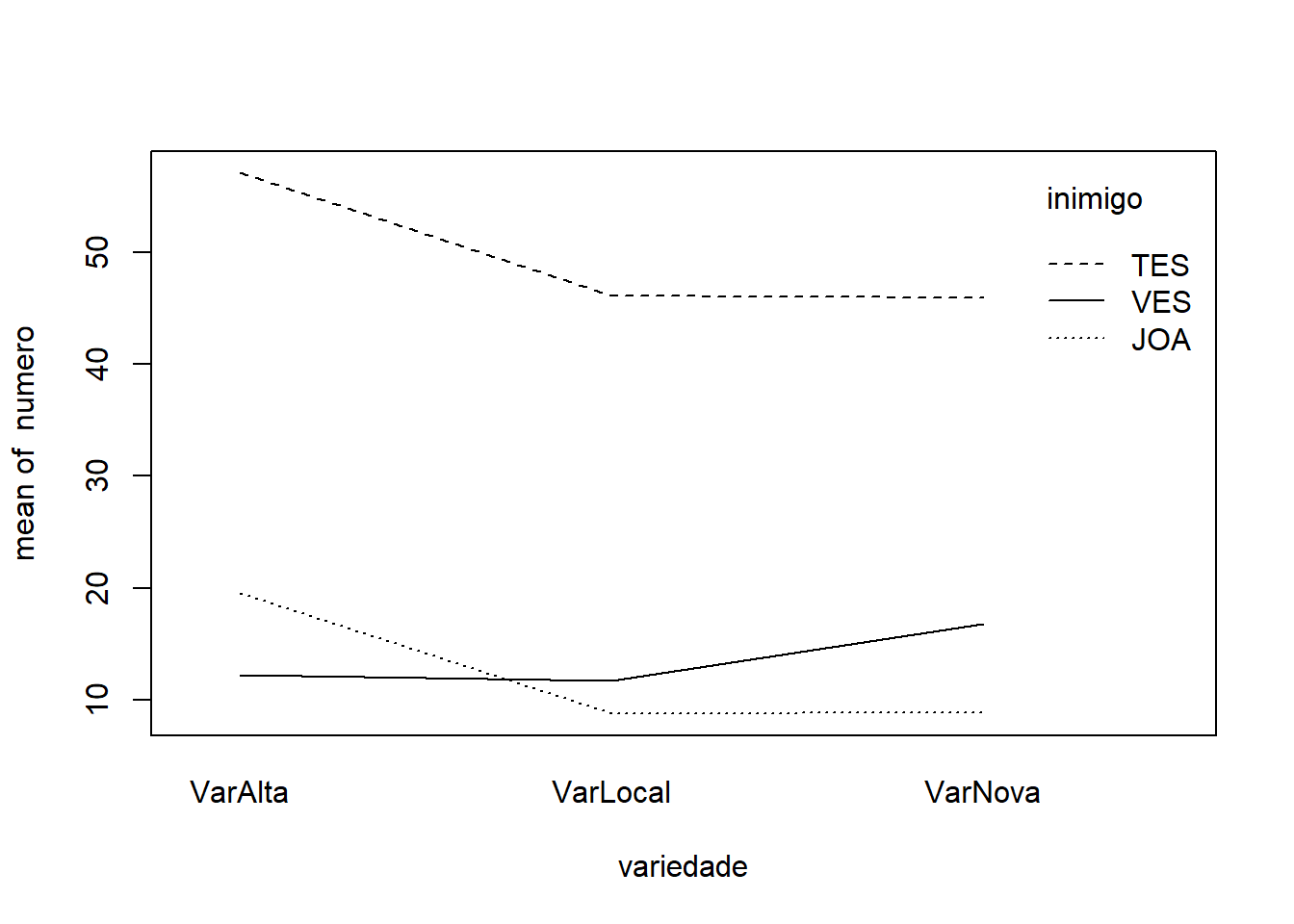
Já o gráfico da interação variedade vs inimigo também mostra linhas não paralelas. O comportamento relativo muda conforme o inimigo natural.
Ambos os gráficos de interação indicam visualmente a presença de uma interação significativa. Os efeitos dos inimigos naturais não parecem ser os mesmos para todas as variedades, e as diferenças entre as variedades mudam dependendo do inimigo natural aplicado.
A análise de variância (ANOVA) revelou que a interação entre o tipo de inimigo natural e a variedade de pimentão foi estatisticamente significativa (p-valor = <0,001) no que diz respeito ao número médio de pulgões por folha. A significância desta interação implica que o efeito dos diferentes inimigos naturais sobre a infestação de pulgões depende da variedade de pimentão, e, reciprocamente, as diferenças de infestação entre as variedades de pimentão são modificadas pela presença ou tipo de inimigo natural.
Apesar da presença desta interação significativa, os efeitos principais de ambos os fatores também foram altamente significativos e apresentaram uma magnitude considerável, especialmente o fator “inimigo”
O tipo de inimigo natural teve um impacto principal extremamente forte e significativo sobre o número de pulgões (p-valor <0,001). De maneira geral, os tratamentos com introdução de inimigos naturais resultaram em uma redução drástica da infestação por pulgões em comparação com o tratamento testemunha.
A variedade de pimentão também exerceu um efeito principal significativo sobre a infestação (p-valor <0,001).
A interação significativa implica que não se pode generalizar o efeito de um inimigo natural sem considerar a variedade, e vice-versa.
No entanto, a força do efeito principal do fator “inimigo” é tão proeminente em comparação com a interação que a conclusão geral de que os inimigos naturais são vastamente superiores à ausência de controle (testemunha) é robusta e de grande importância prática, mesmo que haja variações na magnitude dessa superioridade entre as variedades. Da mesma forma, o efeito principal de “variedade” sugere que existem diferenças consistentes na suscetibilidade das variedades que são importantes, ainda que a interação module essas diferenças.
Portanto, embora a interação possa ser explorada para entender combinações específicas ótimas, as mensagens principais são: (1) o uso dos inimigos naturais testados é altamente eficaz para reduzir a população de pulgões em relação à testemunha, e (2) existem diferenças importantes na suscetibilidade entre as variedades de pimentão.
17.2.1 Testes post-hoc para anova de 2 fatores - interação significativa com efeitos principais dominantes.
Em cenários de interação significativa com efeitos principais dominantes, os testes post-hoc são aplicados a cada efeito principal isoladamente, como se estivessem sendo analisados em estudos de um único fator. Esta abordagem não ignora a interação, mas reconhece que as conclusões mais impactantes e generalizáveis podem emergir da análise individualizada dos efeitos principais.
Exemplo 17.4 (Análise de Variância para dois fatores - interação significativa com efeitos principais dominantes.) .
Teste de Dunnett para o efeito principal do inimigo natual:
# Carregar pacotes se ainda não estiverem carregadospacman::p_load("emmeans")# Calcular as médias marginais estimadas e aplicar o teste de Dunnettdn_inimigo <- emmeans::emmeans(aov_pulgao, ~inimigo,contr ="dunnett",ref =which(names(table(pulgao$inimigo)) =="TES"))
NOTE: Results may be misleading due to involvement in interactions
# Contrastes (comparações contra a testemunha)dn_inimigo$contrasts
contrast estimate SE df t.ratio p.value
JOA - TES -37,4 1,6 24 -23,392 0,0000
VES - TES -36,2 1,6 24 -22,641 0,0000
Results are averaged over the levels of: bloco, variedade
P value adjustment: dunnettx method for 2 tests
# Intervalos de confiança para os contrastesdn_inimigo$contrasts %>%confint()
contrast estimate SE df lower.CL upper.CL
JOA - TES -37,4 1,6 24 -41,1 -33,6
VES - TES -36,2 1,6 24 -39,9 -32,4
Results are averaged over the levels of: bloco, variedade
Confidence level used: 0,95
Conf-level adjustment: dunnettx method for 2 estimates
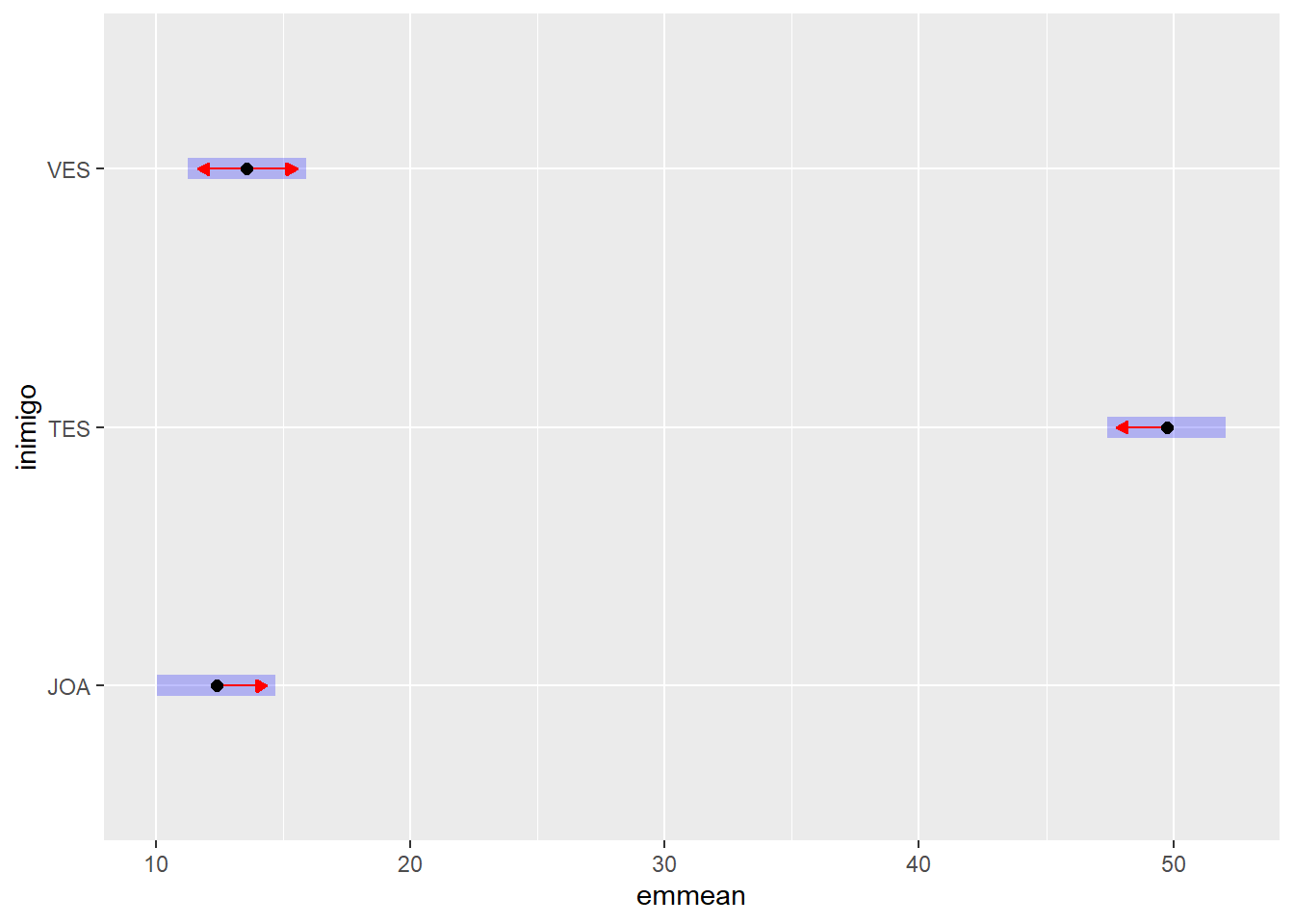
# Médias marginais estimadasdn_inimigo$emmeans
inimigo emmean SE df lower.CL upper.CL
JOA 12,4 1,13 24 10,1 14,7
TES 49,7 1,13 24 47,4 52,1
VES 13,6 1,13 24 11,3 15,9
Results are averaged over the levels of: bloco, variedade
Confidence level used: 0,95
# Gráfico das médias com intervalo de confiançadn_inimigo$emmeans %>%plot(comparisons =TRUE, CIs =TRUE)
Tabela X. Número médio de pulgões por tratamento de controle biológico
Espécie
Número médio de pulgões
JOA
12,39 *
TES
49,74
VES
13,58 *
*Diferença significativa em relação ao controle (teste de Dunnett, 5%).
O teste de Dunnett, com um nível de significância de 5%, foi empregado para comparar os tratamentos com agentes de controle biológico (JOA e VES) diretamente com o grupo testemunha (TES). Tanto o tratamento com Joaninha (JOA) quanto o com Vespa (VES) resultaram em um número médio de pulgões significativamente inferior ao observado no grupo Testemunha (TES). Isso sugere que ambos os agentes de controle biológico foram eficazes na redução da população de pulgões em comparação com a ausência de controle.
Teste de Tukey para o efeito principal da variedade:
# Carregar pacotes se ainda não estiverem carregadospacman::p_load("emmeans", "multcomp", "multcompView")# Calcular as médias marginais estimadas e aplicar o teste de Tukeytk_variedade <- emmeans::emmeans(aov_pulgao, ~variedade, contr ="tukey")
NOTE: Results may be misleading due to involvement in interactions
# Contrastes (comparações par a par)tk_variedade$contrasts
contrast estimate SE df t.ratio p.value
VarAlta - VarLocal 7,41 1,6 24 4,638 0,0003
VarAlta - VarNova 5,74 1,6 24 3,592 0,0040
VarLocal - VarNova -1,67 1,6 24 -1,046 0,5560
Results are averaged over the levels of: bloco, inimigo
P value adjustment: tukey method for comparing a family of 3 estimates
# Intervalos de confiança para os contrastestk_variedade$contrasts |>confint()
contrast estimate SE df lower.CL upper.CL
VarAlta - VarLocal 7,41 1,6 24 3,42 11,39
VarAlta - VarNova 5,74 1,6 24 1,75 9,72
VarLocal - VarNova -1,67 1,6 24 -5,66 2,32
Results are averaged over the levels of: bloco, inimigo
Confidence level used: 0,95
Conf-level adjustment: tukey method for comparing a family of 3 estimates
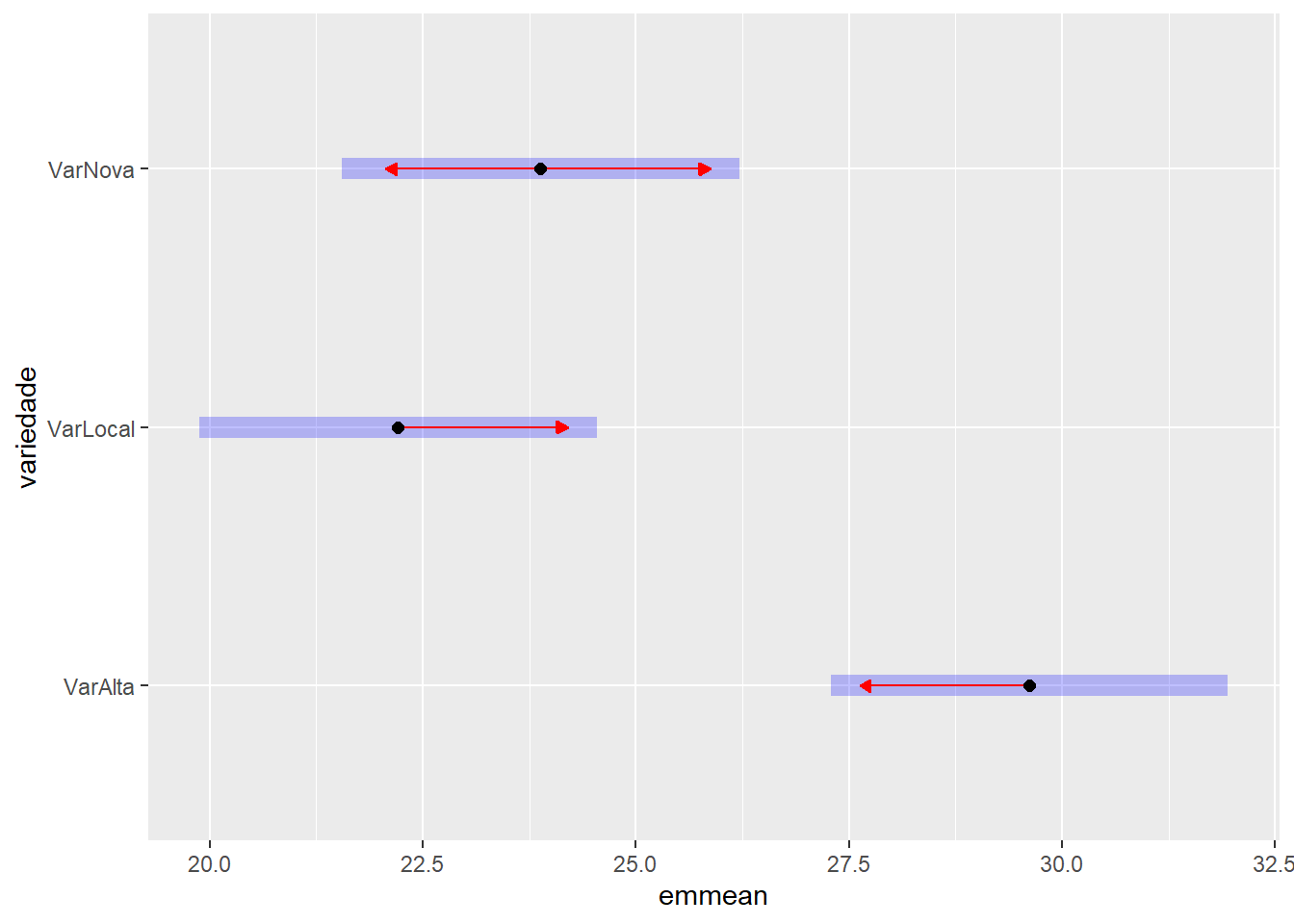
# Médias marginais estimadas e Compact Letter Display (CLD)## Ajustar 'Letters = letters' ou 'Letters = LETTERS' para minúsculas ou maiúsculas## Ajustar decreasing = TRUE para letras decrescentes e decreasing = FALSE para crescentestk_variedade$emmeans |> multcomp::cld(Letters = letters, decreasing =TRUE)
variedade emmean SE df lower.CL upper.CL .group
VarAlta 29,6 1,13 24 27,3 31,9 a
VarNova 23,9 1,13 24 21,6 26,2 b
VarLocal 22,2 1,13 24 19,9 24,5 b
Results are averaged over the levels of: bloco, inimigo
Confidence level used: 0,95
P value adjustment: tukey method for comparing a family of 3 estimates
significance level used: alpha = 0,05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
# Gráfico das médias com intervalo de confiançatk_variedade$emmeans |>plot(comparisons =TRUE, CIs =TRUE)
Tabela X. Número médio de pulgões por variedade de pimentão.
Variedade
Número médio de pulgões
VarAlta
29,62 a
VarNova
23,88 b
VarLocal
22,21 b
Médias com a mesma letra não diferem significativamente (teste de Tukey, 0%)
Conclui-se que a VarAlta foi significativamente mais suscetível à infestação por pulgões em comparação com a VarNova e a VarLocal. Por sua vez, VarNova e VarLocal apresentaram níveis de infestação estatisticamente semelhantes entre si.
17.3 Análise de Variância para dois fatores – interação forte e significativa dominante.
Nesta seção, abordaremos os casos de Análise de Variância (ANOVA) de dois fatores em que a interação entre os fatores não é apenas estatisticamente significativa, mas também se manifesta como o efeito dominante sobre a variável resposta. Diferentemente das situações anteriores, quando uma interação forte e dominante está presente, a interpretação isolada dos efeitos principais pode ser inadequada ou até mesmo enganosa. Isso ocorre porque o efeito de um fator sobre a variável resposta muda consideravelmente dependendo do nível específico do outro fator, tornando os efeitos interdependentes. Assim, o foco da análise e da interpretação se desloca da influência isolada de cada fator para a compreensão de como as combinações específicas dos níveis desses fatores afetam o resultado.
Exemplo 17.5 (Análise de Variância para dois fatores – interação forte e significativa dominante.) A busca por práticas agrícolas que aumentem a saúde do solo e a produtividade das culturas frequentemente envolve a combinação de diferentes manejos. A interação entre o tipo de adubo orgânico aplicado e o manejo da cobertura do solo pode ter efeitos sinérgicos ou antagônicos no desenvolvimento das plantas.
Um experimento foi conduzido para investigar o efeito de diferentes tipos de adubos orgânicos (Fator A) e diferentes tipos de cobertura do solo (Fator B) na produção de biomassa seca da parte aérea de uma cultura de milho (Zea mays L.).
O Fator A (Tipo de Adubo Orgânico) consistiu em 5 níveis:
A0: Controle (sem adubação orgânica)
AE: Esterco Bovino Curtido
AC: Composto Orgânico de Resíduos Vegetais
AV: Vermicomposto (húmus de minhoca)
AB: Biochar (carvão vegetal ativado)
O Fator B (Tipo de Cobertura do Solo) consistiu em 5 níveis:
CSN: Solo Nu (sem cobertura, manejo convencional)
CSP: Cobertura com Palha Seca (mulching orgânico)
CSV: Cobertura Viva com Leguminosa (e.g., crotalária spectabilis semeada nas entrelinhas)
CPP: Cobertura com Plástico Preto (mulching plástico)
CSC: Cobertura com Casca de Arroz Carbonizada
O experimento foi conduzido em campo, utilizando um delineamento com 4 blocos com 4. Cada unidade experimental consistiu em uma parcela de 5m x 3m. Assim, tivemos 5 (Adubos) x 5 (Coberturas) = 25 combinações de tratamento x 4 blocos = 100 unidades experimentais.
A variável resposta foi a produção de biomassa seca da parte aérea (em toneladas por hectare - ton/ha), avaliada na fase de pendoamento do milho.
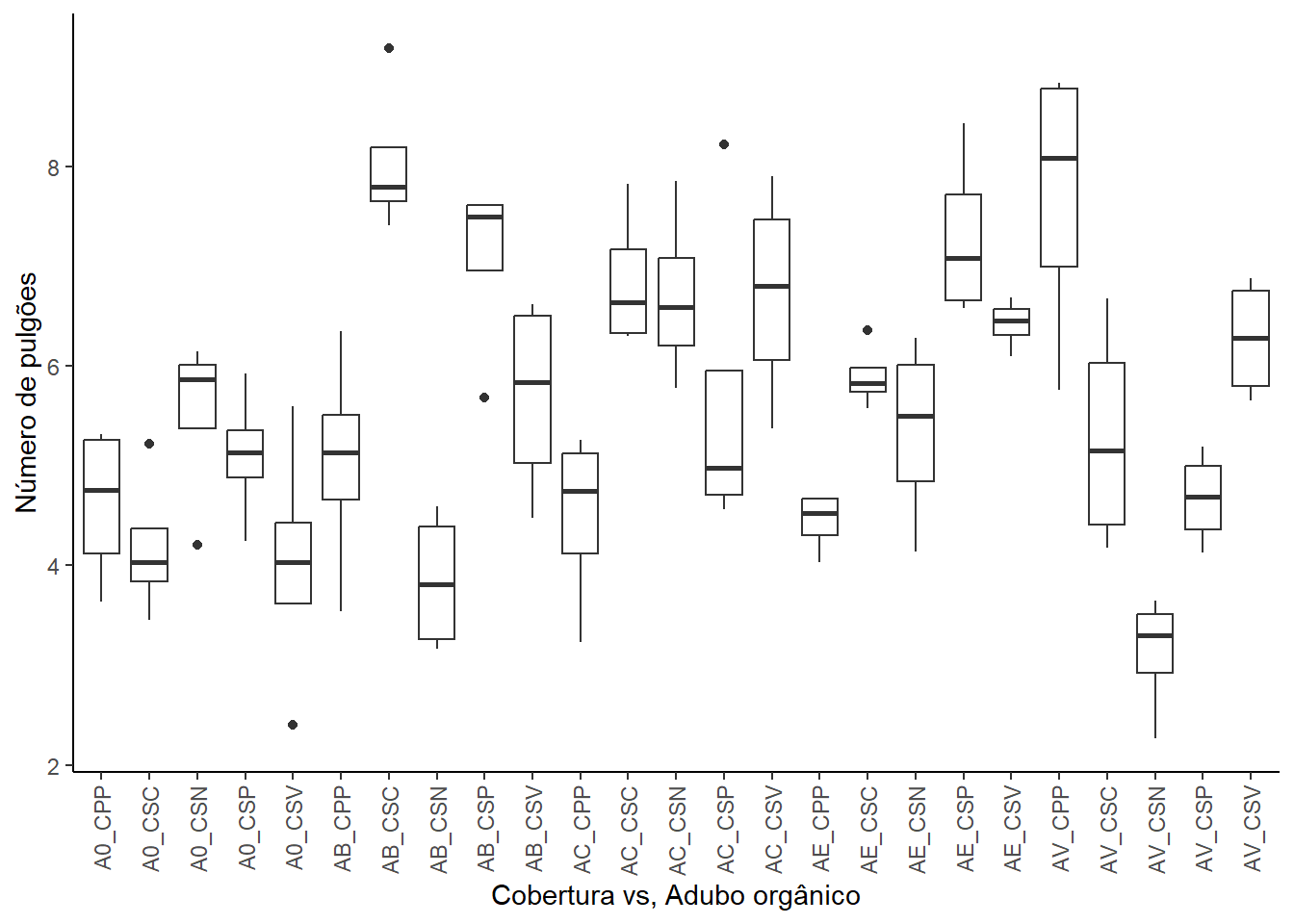
A análise exploratória mostra que o tratamento controle A0 (sem adubação orgânica) resultou na menor média de biomassa. Para os tipos de cobertura, o solo nu (CSN) resultou na menor média de biomassa. Na combinação dos fatores, o tratamento controle (sem adubo orgânico) e com cobertura viva apresentou a menor média, enquanto biochar com casca de arroz carbonizada alcançou a média mais alta.
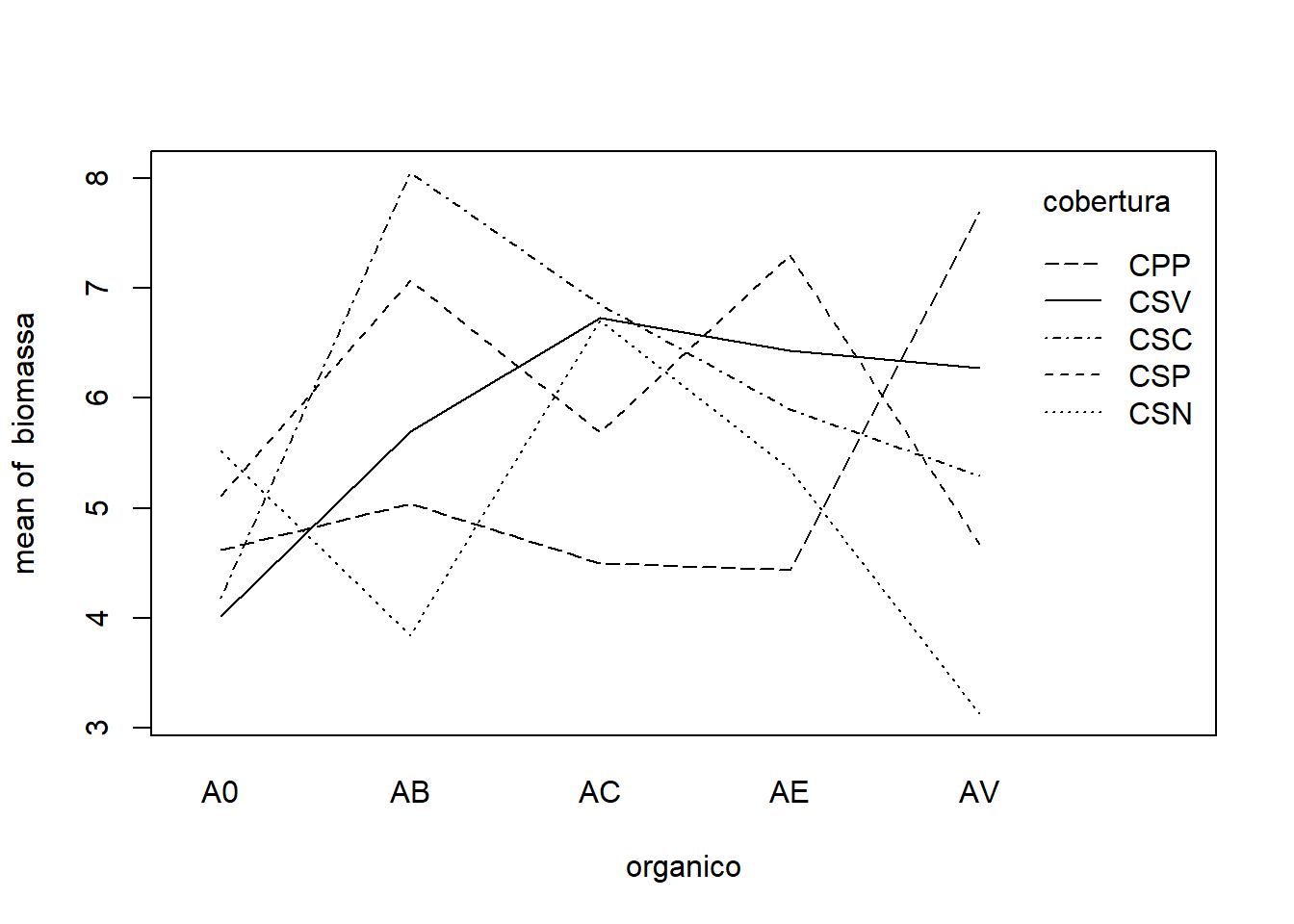
O gráfico da interação adubo orgânico vs cobertura demonstra uma interação muito forte e complexa. As linhas representando os diferentes tipos de cobertura do solo não são de forma alguma paralelas; elas se cruzam repetidamente e mostram picos e vales em diferentes tipos de adubo orgânico. Esta acentuada falta de paralelismo e os múltiplos cruzamentos são uma indicação visual clara de uma interação significativa, em que o melhor tipo de cobertura depende fortemente do adubo orgânico utilizado.
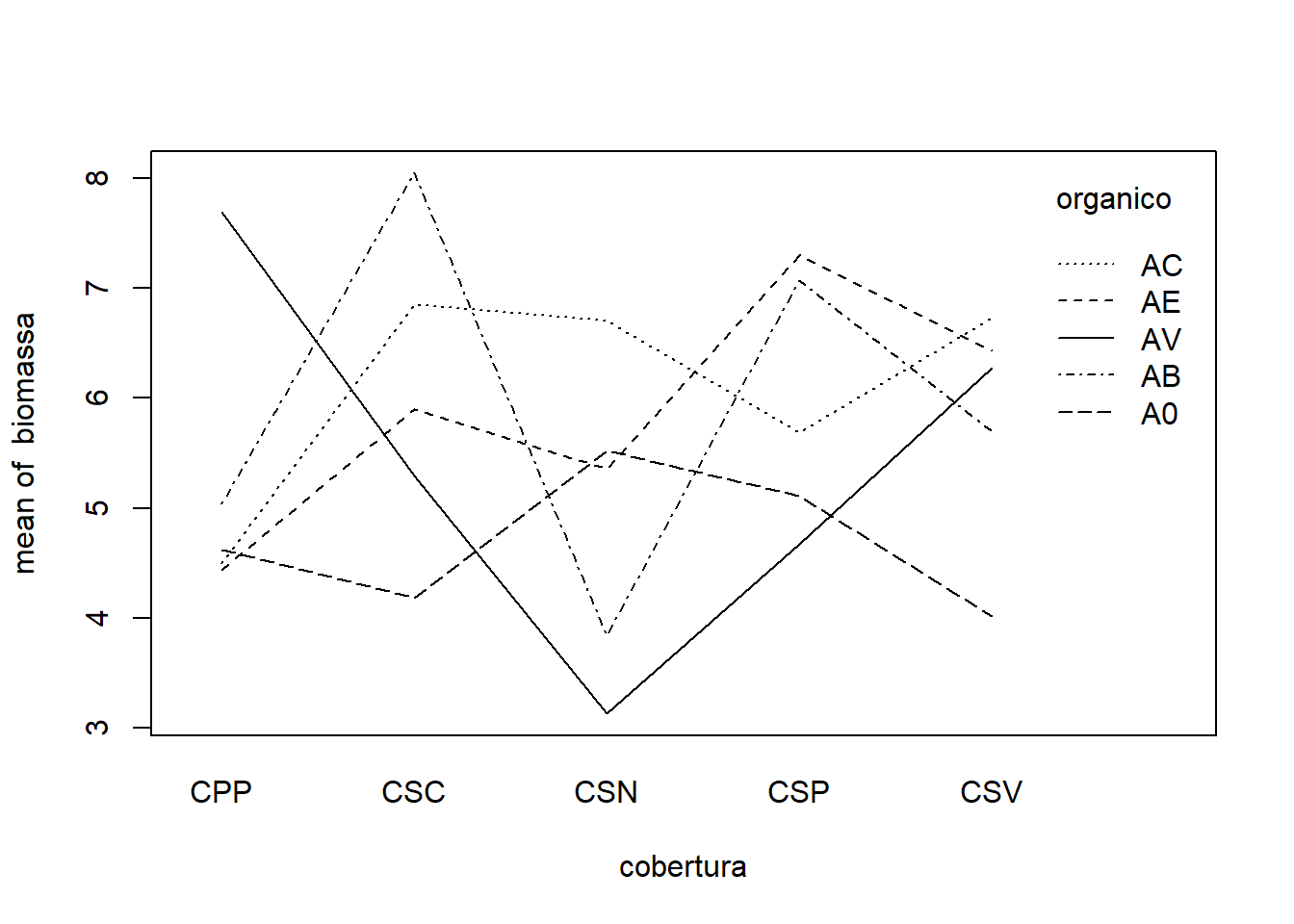
Já o gráfico da interação cobertura vs adubo orgânico também evidencia uma forte interação, ou seja, o “melhor” adubo orgânico é específico para cada tipo de cobertura do solo.
Ambos os gráficos de interação demonstram, de forma inequívoca, a presença de uma interação muito forte e complexa entre o tipo de adubo orgânico e o tipo de cobertura do solo sobre a produção de biomassa do milho. Os efeitos dos fatores são interdependentes e não podem ser compreendidos isoladamente.
A análise de variância (ANOVA) revelou que a interação entre o adubo orgânico e a cobertura do solo foi estatisticamente significativa (p-valor = <0,001) com alta magnitude. Assim, a interação é o efeito dominante que governa a resposta da cultura do milho aos manejos combinados. O efeito de um determinado tipo de adubo orgânico sobre a biomassa do milho depende intrinsecamente do tipo de cobertura de solo com o qual ele é aplicado. Da mesma forma, a eficácia ou o benefício de um tipo de cobertura do solo varia significativamente de acordo com o adubo orgânico utilizado.
Embora os efeitos principais de adubo orgânico (p-valor = <0,001) e cobertura (p-valor = <0,001) também tenham sido estatisticamente significativos, sua interpretação isolada é inadequada e pode ser enganosa devido à força da interação. Não se pode concluir, por exemplo, qual adubo orgânico ou qual tipo de cobertura é “melhor” de forma geral, pois o desempenho ótimo é específico da combinação.
17.3.1 Testes post-hoc para anova de 2 fatores - interação forte e significativa dominante.
Quando a análise de variância (ANOVA) de dois fatores aponta para uma interação forte e estatisticamente significativa, a abordagem correta para os testes post-hoc é proceder com o desdobramento da interação. Este procedimento consiste em examinar o efeito de um fator dentro de cada nível específico do outro fator.
Essa análise permite compreender a natureza específica da interdependência entre os fatores, revelando quais combinações de tratamentos são particularmente eficazes ou ineficazes.
Exemplo 17.6 (Análise de Variância para dois fatores – interação forte e significativa dominante.) .
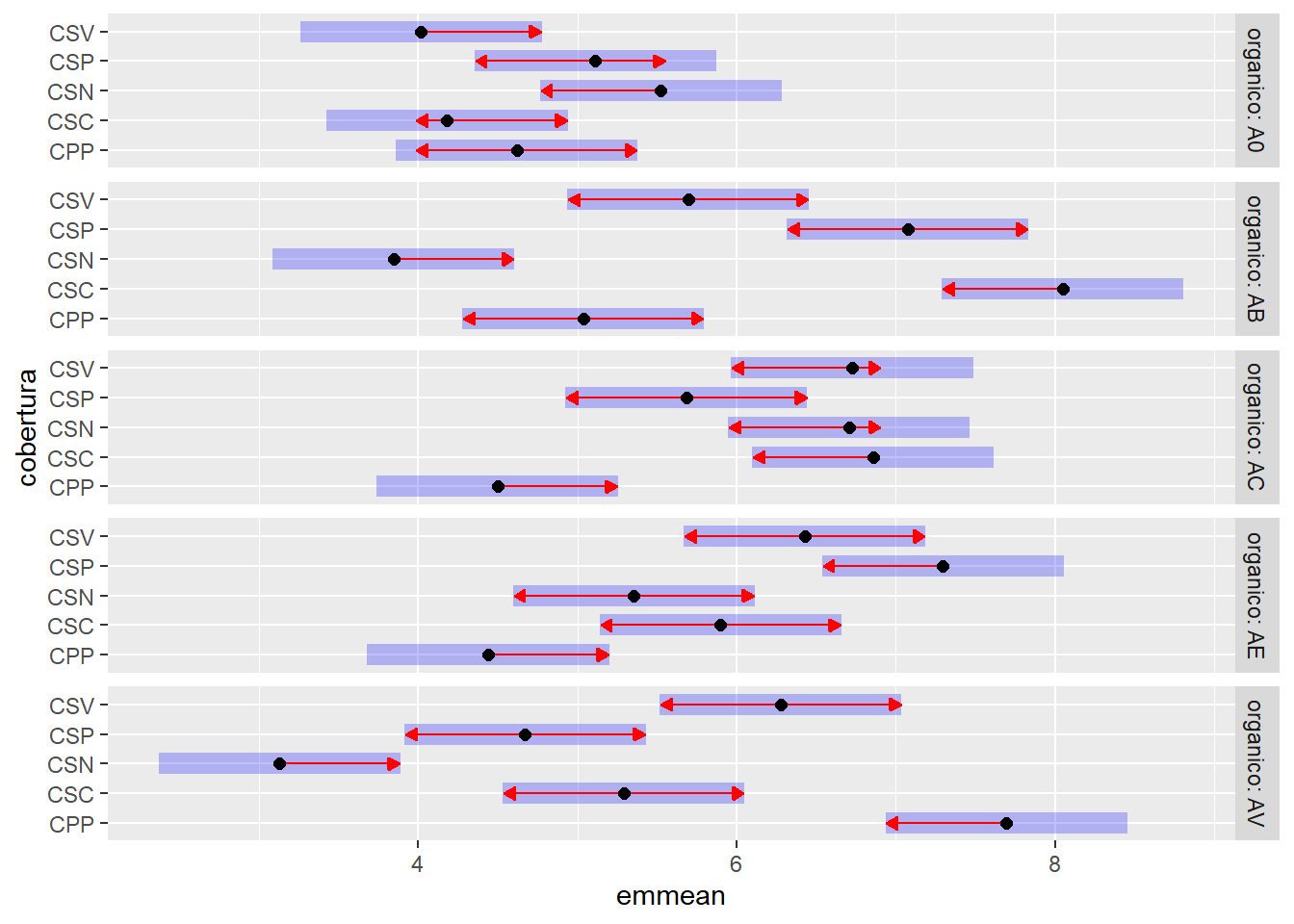
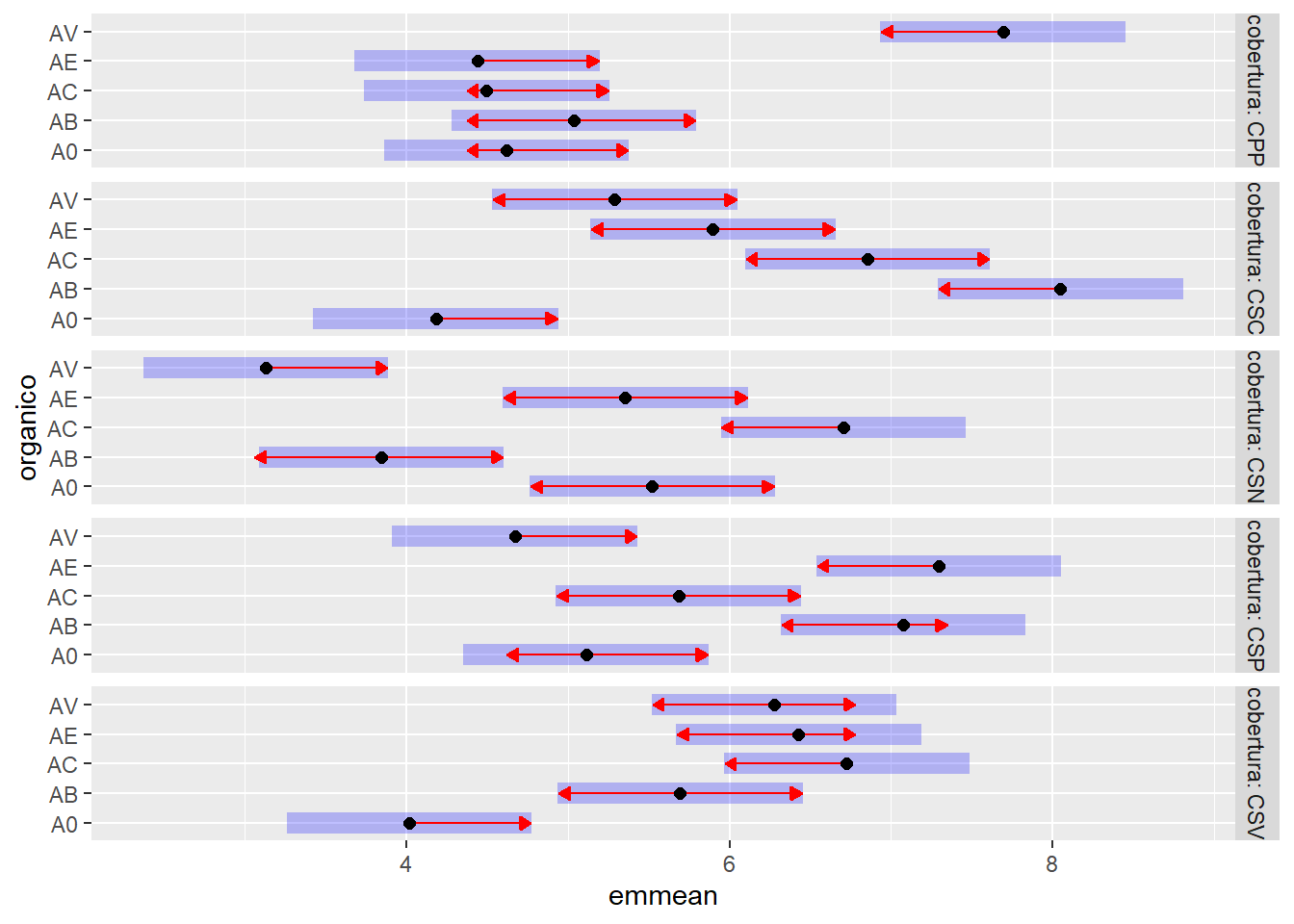
Teste de Tukey para o desdobramento: cobertura dentro de cada nível de adubo orgânico.
# Carregar pacotes se ainda não estiverem carregadospacman::p_load("emmeans", "multcomp", "multcompView")# Calcular as médias marginais estimadas e aplicar o teste de Tukeytk_cobertura_organico <- emmeans::emmeans(aov_milho, ~ cobertura | organico, contr ="tukey")# Contrastes (comparações par a par)tk_cobertura_organico$contrasts
# Médias marginais estimadas e Compact Letter Display (CLD)## Ajustar 'Letters = letters' ou 'Letters = LETTERS' para minúsculas ou maiúsculas## Ajustar decreasing = TRUE para letras decrescentes e decreasing = FALSE para crescentestk_cobertura_organico$emmeans |> multcomp::cld(Letters = letters, decreasing =TRUE)
organico = A0:
cobertura emmean SE df lower.CL upper.CL .group
CSN 5,52 0,381 72 4,76 6,28 a
CSP 5,11 0,381 72 4,35 5,87 a
CPP 4,62 0,381 72 3,86 5,38 a
CSC 4,18 0,381 72 3,42 4,94 a
CSV 4,02 0,381 72 3,26 4,78 a
organico = AB:
cobertura emmean SE df lower.CL upper.CL .group
CSC 8,05 0,381 72 7,29 8,81 a
CSP 7,08 0,381 72 6,32 7,83 ab
CSV 5,70 0,381 72 4,94 6,45 bc
CPP 5,04 0,381 72 4,28 5,80 cd
CSN 3,85 0,381 72 3,09 4,60 d
organico = AC:
cobertura emmean SE df lower.CL upper.CL .group
CSC 6,86 0,381 72 6,10 7,61 a
CSV 6,72 0,381 72 5,97 7,48 a
CSN 6,71 0,381 72 5,95 7,46 a
CSP 5,68 0,381 72 4,93 6,44 ab
CPP 4,50 0,381 72 3,74 5,26 b
organico = AE:
cobertura emmean SE df lower.CL upper.CL .group
CSP 7,29 0,381 72 6,54 8,05 a
CSV 6,43 0,381 72 5,67 7,19 ab
CSC 5,90 0,381 72 5,14 6,66 abc
CSN 5,36 0,381 72 4,60 6,11 bc
CPP 4,44 0,381 72 3,68 5,20 c
organico = AV:
cobertura emmean SE df lower.CL upper.CL .group
CPP 7,69 0,381 72 6,93 8,45 a
CSV 6,28 0,381 72 5,52 7,04 ab
CSC 5,29 0,381 72 4,53 6,05 bc
CSP 4,67 0,381 72 3,91 5,43 c
CSN 3,13 0,381 72 2,37 3,89 d
Results are averaged over the levels of: bloco
Confidence level used: 0,95
P value adjustment: tukey method for comparing a family of 5 estimates
significance level used: alpha = 0,05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
# Gráfico das médias com intervalo de confiançatk_cobertura_organico$emmeans |>plot(comparisons =TRUE, CIs =TRUE)
Teste de Tukey para o desdobramento: adubo orgânico dentro de cada nível de cobertura.
# Carregar pacotes se ainda não estiverem carregadospacman::p_load("emmeans", "multcomp", "multcompView")# Calcular as médias marginais estimadas e aplicar o teste de Tukeytk_organico_cobertura <- emmeans::emmeans(aov_milho, ~ organico | cobertura, contr ="tukey")# Contrastes (comparações par a par)tk_organico_cobertura$contrasts
cobertura = CPP:
contrast estimate SE df t.ratio p.value
A0 - AB -0,4175 0,538 72 -0,776 0,9368
A0 - AC 0,1225 0,538 72 0,228 0,9994
A0 - AE 0,1800 0,538 72 0,334 0,9972
A0 - AV -3,0725 0,538 72 -5,708 0,0000
AB - AC 0,5400 0,538 72 1,003 0,8531
AB - AE 0,5975 0,538 72 1,110 0,8007
AB - AV -2,6550 0,538 72 -4,932 0,0000
AC - AE 0,0575 0,538 72 0,107 1,0000
AC - AV -3,1950 0,538 72 -5,936 0,0000
AE - AV -3,2525 0,538 72 -6,042 0,0000
cobertura = CSC:
contrast estimate SE df t.ratio p.value
A0 - AB -3,8650 0,538 72 -7,180 0,0000
A0 - AC -2,6725 0,538 72 -4,965 0,0000
A0 - AE -1,7150 0,538 72 -3,186 0,0176
A0 - AV -1,1075 0,538 72 -2,057 0,2499
AB - AC 1,1925 0,538 72 2,215 0,1858
AB - AE 2,1500 0,538 72 3,994 0,0014
AB - AV 2,7575 0,538 72 5,123 0,0000
AC - AE 0,9575 0,538 72 1,779 0,3938
AC - AV 1,5650 0,538 72 2,907 0,0377
AE - AV 0,6075 0,538 72 1,129 0,7909
cobertura = CSN:
contrast estimate SE df t.ratio p.value
A0 - AB 1,6775 0,538 72 3,116 0,0214
A0 - AC -1,1825 0,538 72 -2,197 0,1927
A0 - AE 0,1675 0,538 72 0,311 0,9979
A0 - AV 2,3925 0,538 72 4,445 0,0003
AB - AC -2,8600 0,538 72 -5,313 0,0000
AB - AE -1,5100 0,538 72 -2,805 0,0491
AB - AV 0,7150 0,538 72 1,328 0,6746
AC - AE 1,3500 0,538 72 2,508 0,1002
AC - AV 3,5750 0,538 72 6,642 0,0000
AE - AV 2,2250 0,538 72 4,134 0,0009
cobertura = CSP:
contrast estimate SE df t.ratio p.value
A0 - AB -1,9625 0,538 72 -3,646 0,0044
A0 - AC -0,5725 0,538 72 -1,064 0,8244
A0 - AE -2,1825 0,538 72 -4,055 0,0012
A0 - AV 0,4400 0,538 72 0,817 0,9244
AB - AC 1,3900 0,538 72 2,582 0,0845
AB - AE -0,2200 0,538 72 -0,409 0,9940
AB - AV 2,4025 0,538 72 4,463 0,0003
AC - AE -1,6100 0,538 72 -2,991 0,0302
AC - AV 1,0125 0,538 72 1,881 0,3368
AE - AV 2,6225 0,538 72 4,872 0,0001
cobertura = CSV:
contrast estimate SE df t.ratio p.value
A0 - AB -1,6775 0,538 72 -3,116 0,0214
A0 - AC -2,7075 0,538 72 -5,030 0,0000
A0 - AE -2,4100 0,538 72 -4,477 0,0003
A0 - AV -2,2600 0,538 72 -4,199 0,0007
AB - AC -1,0300 0,538 72 -1,914 0,3196
AB - AE -0,7325 0,538 72 -1,361 0,6544
AB - AV -0,5825 0,538 72 -1,082 0,8151
AC - AE 0,2975 0,538 72 0,553 0,9813
AC - AV 0,4475 0,538 72 0,831 0,9200
AE - AV 0,1500 0,538 72 0,279 0,9986
Results are averaged over the levels of: bloco
P value adjustment: tukey method for comparing a family of 5 estimates
# Intervalos de confiança para os contrastestk_organico_cobertura$contrasts |>confint()
cobertura = CPP:
contrast estimate SE df lower.CL upper.CL
A0 - AB -0,4175 0,538 72 -1,9237 1,08866
A0 - AC 0,1225 0,538 72 -1,3837 1,62867
A0 - AE 0,1800 0,538 72 -1,3262 1,68616
A0 - AV -3,0725 0,538 72 -4,5787 -1,56634
AB - AC 0,5400 0,538 72 -0,9662 2,04616
AB - AE 0,5975 0,538 72 -0,9087 2,10366
AB - AV -2,6550 0,538 72 -4,1612 -1,14884
AC - AE 0,0575 0,538 72 -1,4487 1,56367
AC - AV -3,1950 0,538 72 -4,7012 -1,68884
AE - AV -3,2525 0,538 72 -4,7587 -1,74633
cobertura = CSC:
contrast estimate SE df lower.CL upper.CL
A0 - AB -3,8650 0,538 72 -5,3712 -2,35884
A0 - AC -2,6725 0,538 72 -4,1787 -1,16633
A0 - AE -1,7150 0,538 72 -3,2212 -0,20883
A0 - AV -1,1075 0,538 72 -2,6137 0,39866
AB - AC 1,1925 0,538 72 -0,3137 2,69867
AB - AE 2,1500 0,538 72 0,6438 3,65617
AB - AV 2,7575 0,538 72 1,2513 4,26366
AC - AE 0,9575 0,538 72 -0,5487 2,46367
AC - AV 1,5650 0,538 72 0,0588 3,07117
AE - AV 0,6075 0,538 72 -0,8987 2,11367
cobertura = CSN:
contrast estimate SE df lower.CL upper.CL
A0 - AB 1,6775 0,538 72 0,1713 3,18366
A0 - AC -1,1825 0,538 72 -2,6887 0,32366
A0 - AE 0,1675 0,538 72 -1,3387 1,67366
A0 - AV 2,3925 0,538 72 0,8863 3,89866
AB - AC -2,8600 0,538 72 -4,3662 -1,35383
AB - AE -1,5100 0,538 72 -3,0162 -0,00383
AB - AV 0,7150 0,538 72 -0,7912 2,22117
AC - AE 1,3500 0,538 72 -0,1562 2,85616
AC - AV 3,5750 0,538 72 2,0688 5,08117
AE - AV 2,2250 0,538 72 0,7188 3,73116
cobertura = CSP:
contrast estimate SE df lower.CL upper.CL
A0 - AB -1,9625 0,538 72 -3,4687 -0,45633
A0 - AC -0,5725 0,538 72 -2,0787 0,93366
A0 - AE -2,1825 0,538 72 -3,6887 -0,67634
A0 - AV 0,4400 0,538 72 -1,0662 1,94616
AB - AC 1,3900 0,538 72 -0,1162 2,89616
AB - AE -0,2200 0,538 72 -1,7262 1,28617
AB - AV 2,4025 0,538 72 0,8963 3,90867
AC - AE -1,6100 0,538 72 -3,1162 -0,10383
AC - AV 1,0125 0,538 72 -0,4937 2,51866
AE - AV 2,6225 0,538 72 1,1163 4,12866
cobertura = CSV:
contrast estimate SE df lower.CL upper.CL
A0 - AB -1,6775 0,538 72 -3,1837 -0,17133
A0 - AC -2,7075 0,538 72 -4,2137 -1,20134
A0 - AE -2,4100 0,538 72 -3,9162 -0,90384
A0 - AV -2,2600 0,538 72 -3,7662 -0,75384
AB - AC -1,0300 0,538 72 -2,5362 0,47617
AB - AE -0,7325 0,538 72 -2,2387 0,77367
AB - AV -0,5825 0,538 72 -2,0887 0,92366
AC - AE 0,2975 0,538 72 -1,2087 1,80367
AC - AV 0,4475 0,538 72 -1,0587 1,95366
AE - AV 0,1500 0,538 72 -1,3562 1,65617
Results are averaged over the levels of: bloco
Confidence level used: 0,95
Conf-level adjustment: tukey method for comparing a family of 5 estimates
# Médias marginais estimadas e Compact Letter Display (CLD)## Ajustar 'Letters = letters' ou 'Letters = LETTERS' para minúsculas ou maiúsculas## Ajustar decreasing = TRUE para letras decrescentes e decreasing = FALSE para crescentestk_organico_cobertura$emmeans |> multcomp::cld(Letters = LETTERS, decreasing =TRUE)
cobertura = CPP:
organico emmean SE df lower.CL upper.CL .group
AV 7,69 0,381 72 6,93 8,45 A
AB 5,04 0,381 72 4,28 5,80 B
A0 4,62 0,381 72 3,86 5,38 B
AC 4,50 0,381 72 3,74 5,26 B
AE 4,44 0,381 72 3,68 5,20 B
cobertura = CSC:
organico emmean SE df lower.CL upper.CL .group
AB 8,05 0,381 72 7,29 8,81 A
AC 6,86 0,381 72 6,10 7,61 AB
AE 5,90 0,381 72 5,14 6,66 BC
AV 5,29 0,381 72 4,53 6,05 CD
A0 4,18 0,381 72 3,42 4,94 D
cobertura = CSN:
organico emmean SE df lower.CL upper.CL .group
AC 6,71 0,381 72 5,95 7,46 A
A0 5,52 0,381 72 4,76 6,28 A
AE 5,36 0,381 72 4,60 6,11 A
AB 3,85 0,381 72 3,09 4,60 B
AV 3,13 0,381 72 2,37 3,89 B
cobertura = CSP:
organico emmean SE df lower.CL upper.CL .group
AE 7,29 0,381 72 6,54 8,05 A
AB 7,08 0,381 72 6,32 7,83 AB
AC 5,68 0,381 72 4,93 6,44 BC
A0 5,11 0,381 72 4,35 5,87 C
AV 4,67 0,381 72 3,91 5,43 C
cobertura = CSV:
organico emmean SE df lower.CL upper.CL .group
AC 6,72 0,381 72 5,97 7,48 A
AE 6,43 0,381 72 5,67 7,19 A
AV 6,28 0,381 72 5,52 7,04 A
AB 5,70 0,381 72 4,94 6,45 A
A0 4,02 0,381 72 3,26 4,78 B
Results are averaged over the levels of: bloco
Confidence level used: 0,95
P value adjustment: tukey method for comparing a family of 5 estimates
significance level used: alpha = 0,05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
# Gráfico das médias com intervalo de confiançatk_organico_cobertura$emmeans |>plot(comparisons =TRUE, CIs =TRUE)
Tabela X. Biomassa (ton/ha) média de milho na interação adubo orgânico vs. cobertura do solo.
cobertura
organico
A0
AB
AC
AE
AV
CSN
5,52 a A
3,84 d B
6,71 a A
5,36 bc A
3,13 d B
CSP
5,11 a C
7,08 ab AB
5,69 ab BC
7,30 a A
4,67 c C
CPP
4,62 a B
5,04 cd B
4,50 b B
4,44 c B
7,69 a A
CSC
4,18 a D
8,05 a A
6,86 a AB
5,90 abc BC
5,29 bc CD
CSV
4,02 a B
5,70 bc A
6,73 a A
6,43 ab A
6,28 ab A
Médias com a mesma letra não diferem significativamente (teste de Tukey, 5%): minúscula para comparações em colunas, Maiúscula para comparações em linhas.
A tabela é o resultado do desdobramento da interação.
Por exemplo, observando a linha “CSN” (Solo Nu):
Os adubos A0, AC e AE não apresentam diferenças significativas entre si na produção de biomassa. No entanto, esses três são significativamente diferentes (e superiores, neste caso) aos adubos AB e AV, que por sua vez não diferem entre si.
Analisando a coluna “AV” (Vermicomposto):
A cobertura CPP (Plástico Preto) proporcionou a maior biomassa, diferindo significativamente de todas as outras coberturas para este adubo, exceto CSV.
A cobertura CSN (Solo Nu) foi a que apresentou o menor desempenho com o Vermicomposto.