A Análise de Variância (ANOVA) (e os testes t) são ferramentas estatísticas fundamentais para comparar médias entre dois ou mais grupos. Esses métodos são poderosos quando seus pressupostos são atendidos, como a normalidade dos resíduos e a homogeneidade das variâncias. No entanto, na pesquisa em ciências agrárias, biológicas e ambientais, frequentemente nos deparamos com dados que não se encaixam perfeitamente nesses moldes
Muitas variáveis resposta de interesse não seguem uma distribuição normal, ou suas variâncias não são constantes entre os grupos. Pense, por exemplo, em:
Dados de contagem: número de insetos-praga por planta, número de lesões de doença em uma folha, ou o número de ninhos de uma espécie de ave em diferentes habitats. Esses dados são discretos, não negativos, e sua variância muitas vezes aumenta com a média.
Dados binomiais: proporção de sementes germinadas, presença ou ausência de uma doença em um indivíduo, ou sucesso/falha de um tratamento. Esses dados são limitados a um intervalo (e.g., 0 a 1 para proporções).
Tentar ajustar modelos lineares clássicos a esses tipos de dados pode levar a predições irrealistas (como contagens negativas), erros padrão incorretos e, consequentemente, a conclusões estatísticas equivocadas. É aqui que entram os Modelos Lineares Generalizados (GLM), que nos permitem analisar uma gama muito mais ampla de variáveis resposta. Eles mantêm a estrutura familiar de um preditor linear, mas introduzem duas modificações cruciais:
Componente Aleatório: A variável resposta não precisa seguir uma distribuição Normal. Em vez disso, ela pode pertencer a uma família mais ampla de distribuições, conhecida como família exponencial, que inclui distribuições como Poisson (para contagens), Binomial (para proporções/binários), Gama (para dados contínuos assimétricos positivos), entre outras.
Função de Ligação: Uma função de ligação é utilizada para conectar a média da variável resposta ao preditor linear. Isso permite que a média da resposta seja modelada de forma não linear em relação aos preditores, ao mesmo tempo que garante que as predições da média permaneçam dentro dos limites válidos para a distribuição escolhida (e.g., contagens sempre positivas).
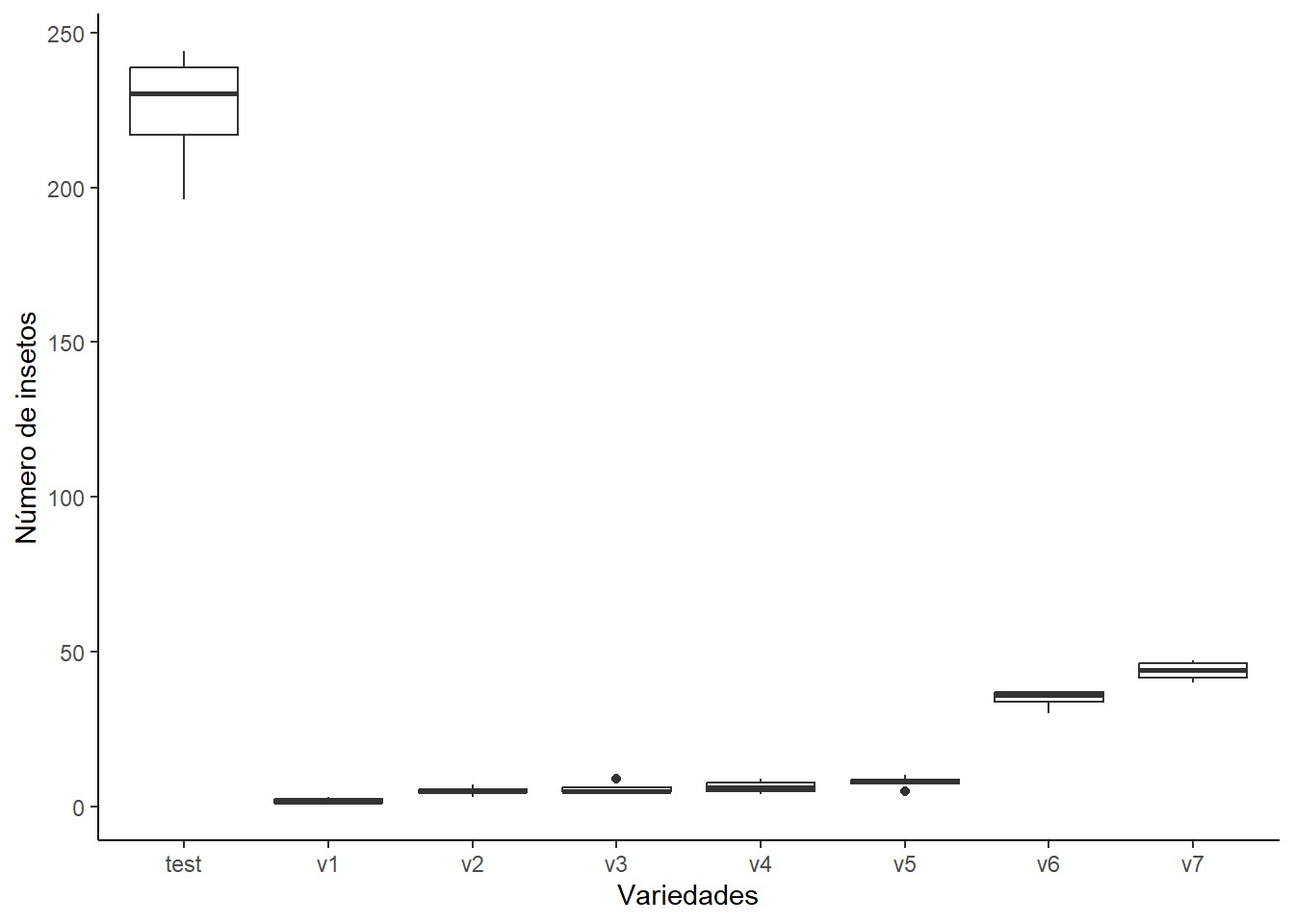
Exemplo 18.1 (GLM - distribuição de Poisson) No manejo integrado de pragas, a seleção de variedades ou genótipos de plantas menos suscetíveis ao ataque de insetos-praga é uma estratégia fundamental. Um grupo de pesquisadores em entomologia agrícola está investigando a resposta de uma espécie de besouro-praga a diferentes genótipos de uma determinada cultura. O objetivo é identificar se alguns genótipos são mais ou menos preferidos (ou suscetíveis) pelo besouro, o que poderia ter implicações diretas para programas de melhoramento genético e recomendações de plantio.
Para avaliar essa questão, foi conduzido um experimento com oito diferentes genótipos da planta hospedeira. Após um período de exposição padronizado, o número de besouros adultos encontrados em cada unidade experimental foi contado. Os dados estão no arquivo besouro.csv.
Dado que a variável resposta é uma contagem, um Modelo Linear Generalizado (GLM) com distribuição de Poisson e função de ligação logarítmica é proposto como a abordagem adequada para investigar o efeito do fator variedade sobre o número de insetos.
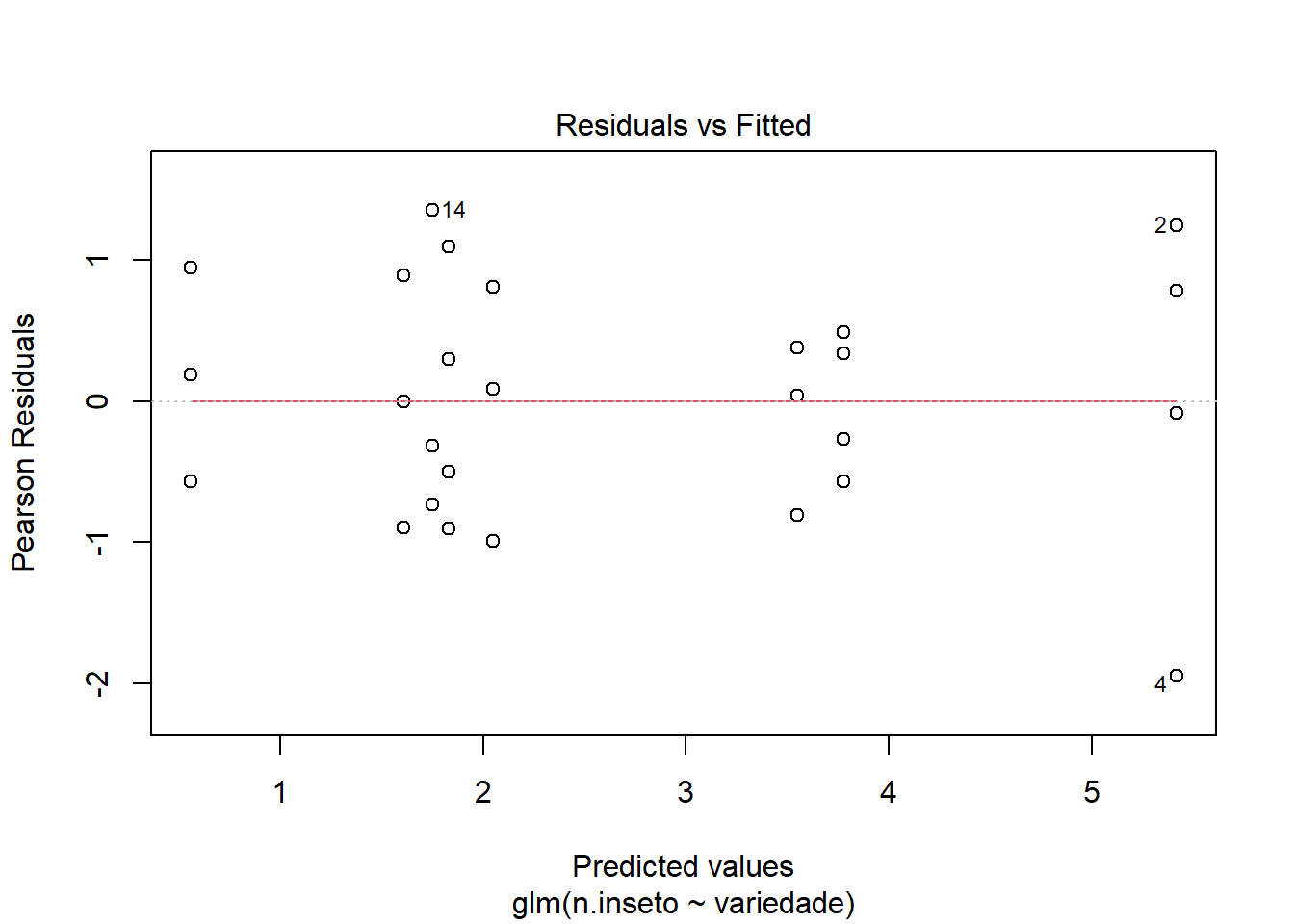
# Verificar o Índice de dispersão: razão Deviance Residual / Graus de Liberdade Residuais.# Se este valor for > 1.5-2.0, a superdispersão pode ser um problema.deviance(glm_besouro) /df.residual(glm_besouro)
[1] 0,726811
# Gráfico de Resíduos vs. Valores Ajustados# Resíduos não devem mostrar padrões sistemáticosplot(glm_besouro, which =1)
Teste de Tukey para o efeito da variedade
# Carregar pacotes se ainda não estiverem carregadospacman::p_load("emmeans", "multcomp", "multcompView")# Calcular as médias marginais estimadas e aplicar o teste de Tukeytk_variedade <- emmeans::emmeans(glm_besouro, ~variedade, contr ="tukey")# Contrastes (comparações par a par)tk_variedade$contrasts
# Médias marginais estimadas e Compact Letter Display (CLD)## Ajustar 'Letters = letters' ou 'Letters = LETTERS' para minúsculas ou maiúsculas## Ajustar decreasing = TRUE para letras decrescentes e decreasing = FALSE para crescentestk_variedade$emmeans |> multcomp::cld(Letters = letters, decreasing =TRUE)
variedade emmean SE df asymp.LCL asymp.UCL .group
test 5,42 0,0333 Inf 5,352 5,48 a
v7 3,78 0,0756 Inf 3,630 3,93 b
v6 3,55 0,0848 Inf 3,382 3,71 b
v5 2,05 0,1800 Inf 1,696 2,40 c
v4 1,83 0,2000 Inf 1,441 2,22 cd
v3 1,75 0,2090 Inf 1,341 2,16 cd
v2 1,61 0,2240 Inf 1,171 2,05 cd
v1 0,56 0,3780 Inf -0,181 1,30 d
Results are given on the log (not the response) scale.
Confidence level used: 0,95
P value adjustment: tukey method for comparing a family of 8 estimates
significance level used: alpha = 0,05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
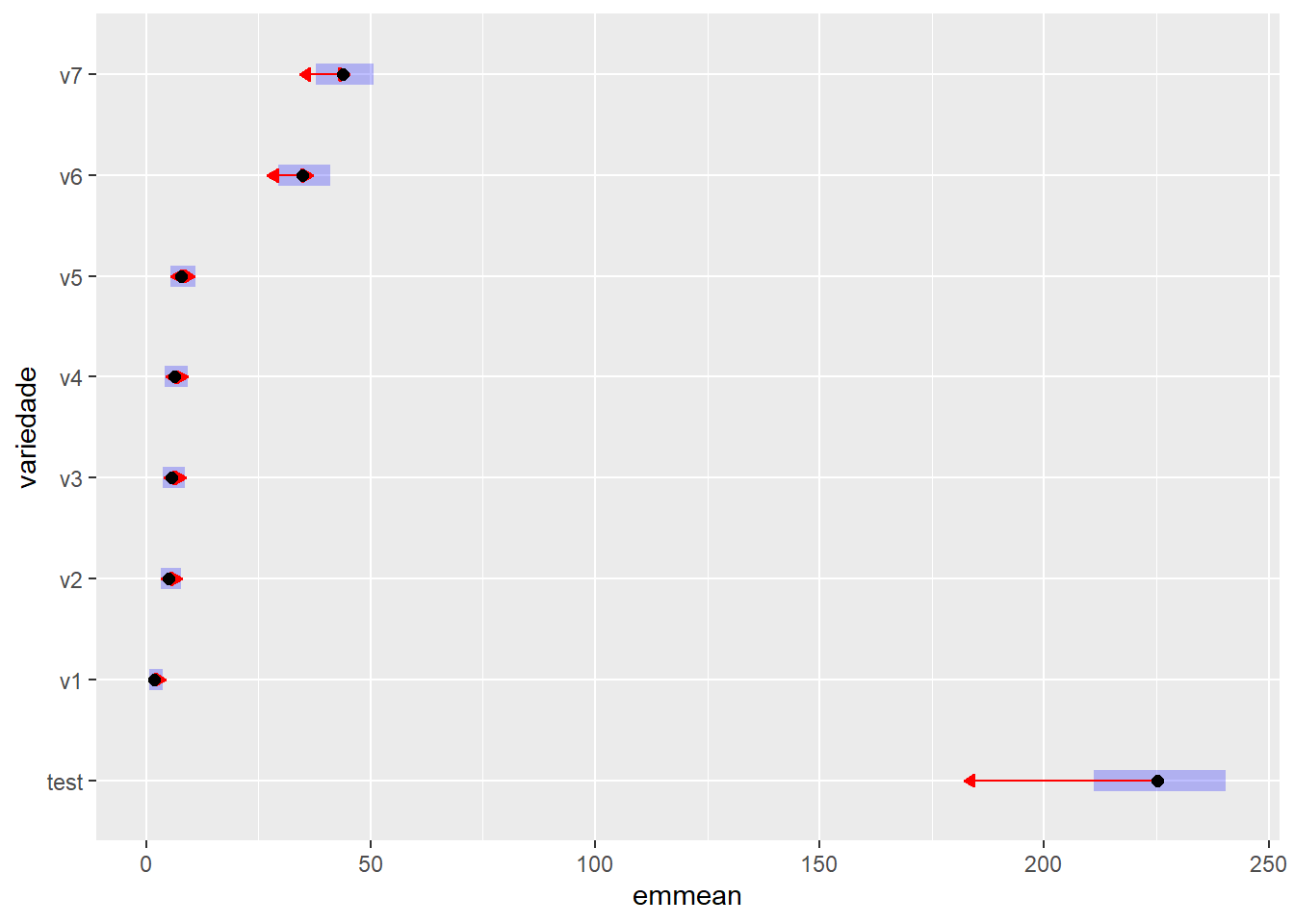
tk_variedade$emmeans |> multcomp::cld(Letters = letters, decreasing =TRUE, type ="response")
variedade rate SE df asymp.LCL asymp.UCL .group
test 225,25 7,500 Inf 211,012 240,45 a
v7 43,75 3,310 Inf 37,725 50,74 b
v6 34,75 2,950 Inf 29,428 41,03 b
v5 7,75 1,390 Inf 5,450 11,02 c
v4 6,25 1,250 Inf 4,223 9,25 cd
v3 5,75 1,200 Inf 3,821 8,65 cd
v2 5,00 1,120 Inf 3,226 7,75 cd
v1 1,75 0,661 Inf 0,834 3,67 d
Confidence level used: 0,95
Intervals are back-transformed from the log scale
P value adjustment: tukey method for comparing a family of 8 estimates
Tests are performed on the log scale
significance level used: alpha = 0,05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
# Gráfico das médias com intervalo de confiançatk_variedade$emmeans |>plot(comparisons =TRUE, CIs =TRUE, type ="response")
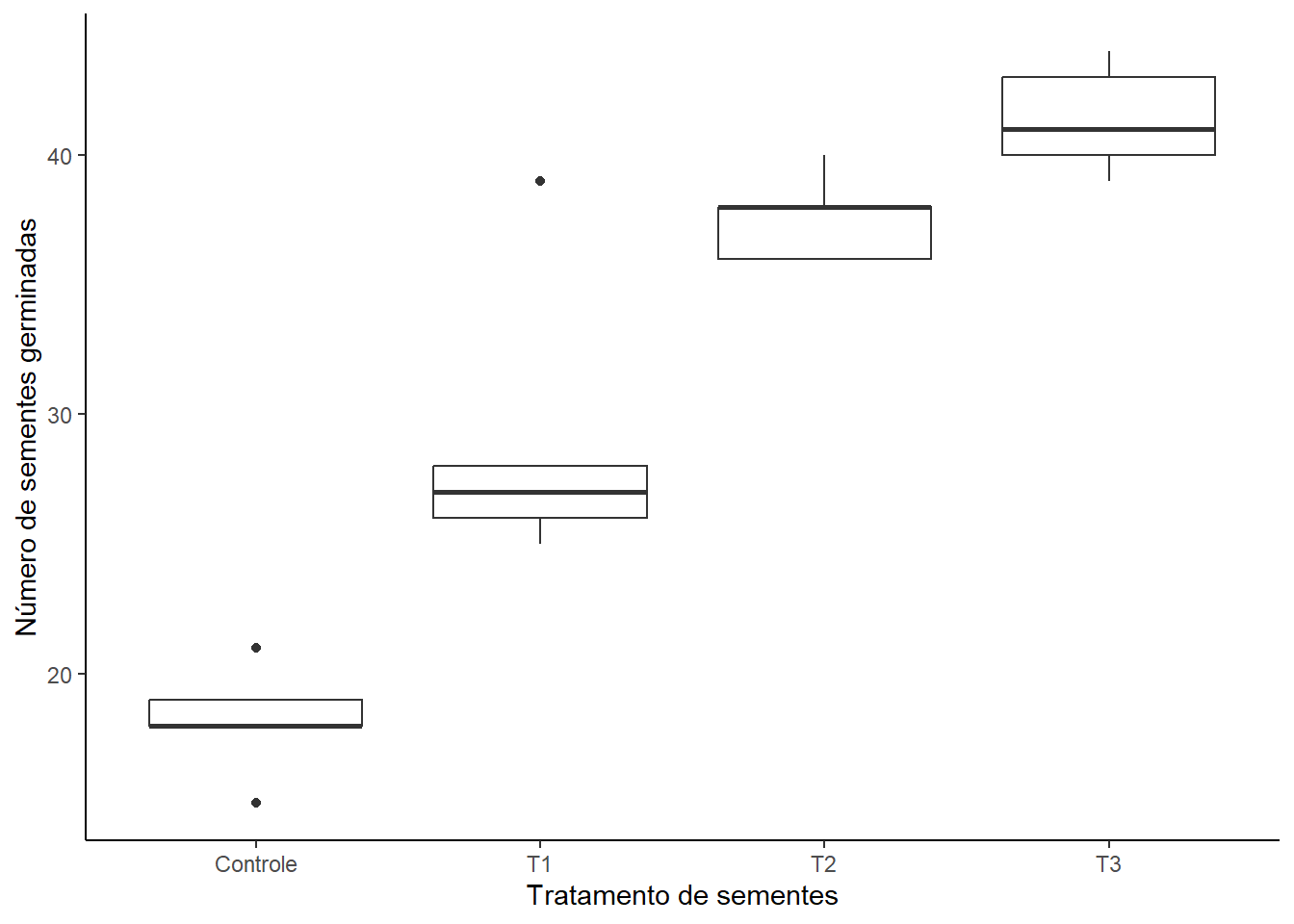
Exemplo 18.2 (GLM - Distribuição binomial) Uma empresa de sementes está desenvolvendo e testando novos tratamentos para melhorar a taxa de germinação de uma espécie de hortaliça de alto valor comercial. Quatro tratamentos (um controle e três novos tratamentos experimentais: T1, T2, T3) foram aplicados a lotes de sementes.
Para cada um dos quatro tratamentos, foram preparadas cinco repetições (caixas de germinação). Em cada repetição, um número fixo de 50 sementes foi semeado. Após um período de incubação, contou-se o número de sementes que germinaram em cada uma das unidades experimentais. Os dados estão no arquivo germinacao.csv.
Os pesquisadores desejam determinar se existem diferenças estatisticamente significativas na proporção média de germinação entre os diferentes tratamentos. Dado que a variável resposta é o número de sementes germinadas de um total conhecido, um Modelo Linear Generalizado (GLM) com distribuição Binomial e função de ligação logística (logit) é a abordagem apropriada para investigar o efeito do fator tratamento sobre a proporção de germinação.
# A tibble: 4 × 5
tratamento n media desvpad var
<fct> <int> <dbl> <dbl> <dbl>
1 Controle 5 18.2 2.17 4.7
2 T1 5 29 5.70 32.5
3 T2 5 37.6 1.67 2.8
4 T3 5 41.4 2.07 4.3
Boxplot comparativo entre os grupos
germinacao |>ggplot(aes(x = tratamento, y = germinadas)) +geom_boxplot() +labs(x ="Tratamento de sementes",y ="Número de sementes germinadas" ) +theme_classic()
Ajuste do modelo com distribuição Binomial
# A variável resposta para family=binomial pode ser uma matriz de duas colunas:# coluna 1 = número de sucessos (germinadas)# coluna 2 = número de fracassos (nao_germinadas)# Alternativamente, pode ser uma proporção (germinadas/total_sementes)# com a variável total_sementes passada para o argumento 'weights'.# A abordagem com matriz de duas colunas é geralmente preferida.glm_germinacao <-glm(cbind(germinadas, nao_germinadas) ~ tratamento,family =binomial(link ="logit"),data = germinacao)anova(glm_germinacao)
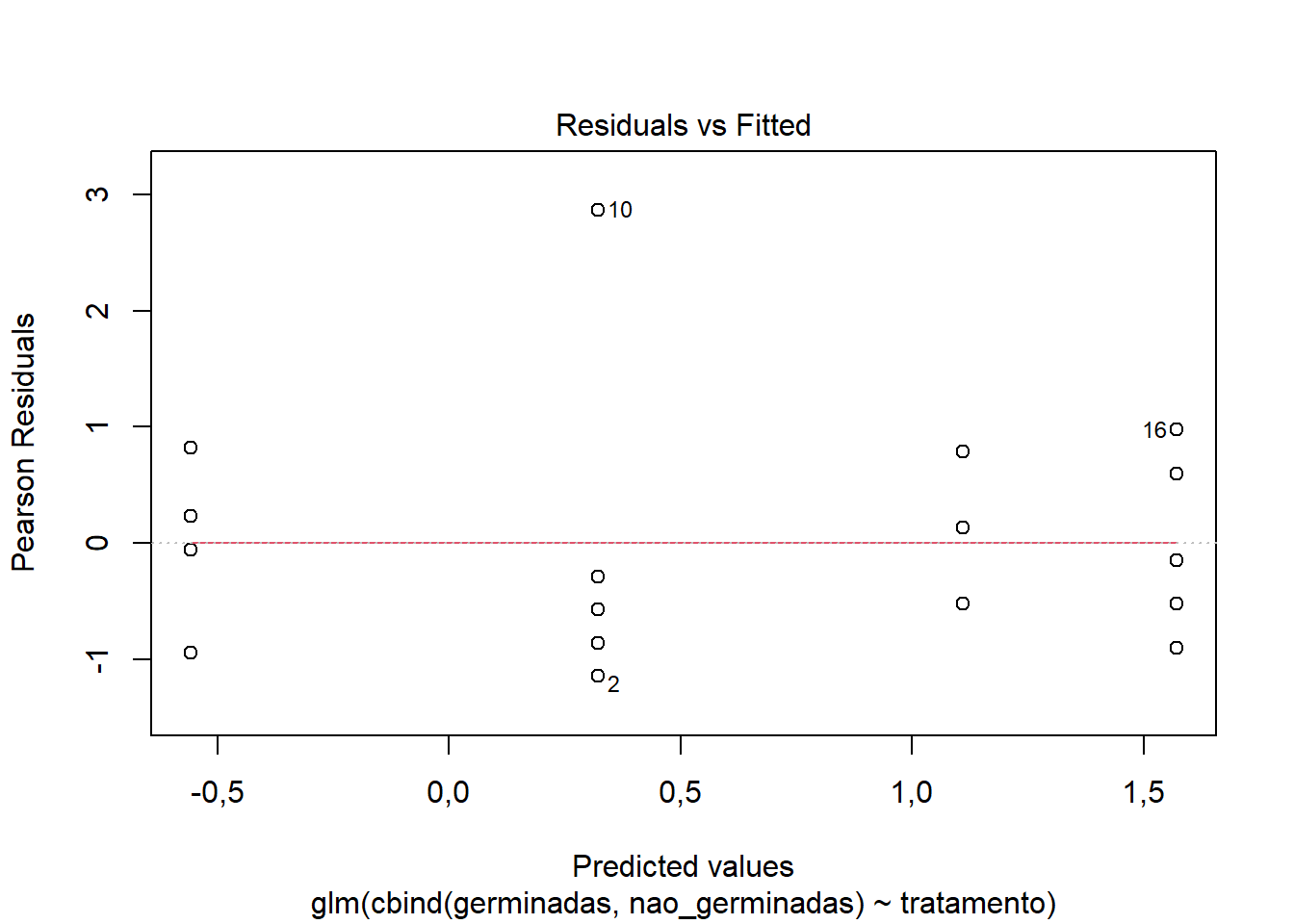
# Verificar o Índice de dispersão (Overdispersion)# Para dados binomiais, idealmente próximo de 1.# Valores > 1.5-2.0 podem indicar superdispersão.deviance(glm_germinacao) /df.residual(glm_germinacao)
[1] 1,03965
# Gráfico de Resíduos vs. Valores Ajustados# Resíduos não devem mostrar padrões sistemáticosplot(glm_germinacao, which =1)
Teste de Tukey para o efeito do tratamento de sementes
# Carregar pacotes se ainda não estiverem carregadospacman::p_load("emmeans", "multcomp", "multcompView")# Calcular as médias marginais estimadas e aplicar o teste de Tukeytk_germinacao <- emmeans::emmeans(glm_germinacao, ~tratamento, contr ="tukey")# Contrastes (comparações par a par)tk_germinacao$contrasts
contrast estimate SE df z.ratio p.value
Controle - T1 -0,881 0,184 Inf -4,798 0,0000
Controle - T2 -1,667 0,197 Inf -8,473 0,0000
Controle - T3 -2,130 0,213 Inf -9,998 0,0000
T1 - T2 -0,787 0,195 Inf -4,042 0,0003
T1 - T3 -1,249 0,211 Inf -5,919 0,0000
T2 - T3 -0,462 0,223 Inf -2,077 0,1607
Results are given on the log odds ratio (not the response) scale.
P value adjustment: tukey method for comparing a family of 4 estimates
# Intervalos de confiança para os contrastestk_germinacao$contrasts |>confint()
contrast estimate SE df asymp.LCL asymp.UCL
Controle - T1 -0,881 0,184 Inf -1,35 -0,409
Controle - T2 -1,667 0,197 Inf -2,17 -1,162
Controle - T3 -2,130 0,213 Inf -2,68 -1,582
T1 - T2 -0,787 0,195 Inf -1,29 -0,287
T1 - T3 -1,249 0,211 Inf -1,79 -0,707
T2 - T3 -0,462 0,223 Inf -1,03 0,110
Results are given on the log odds ratio (not the response) scale.
Confidence level used: 0,95
Conf-level adjustment: tukey method for comparing a family of 4 estimates
# Médias marginais estimadas e Compact Letter Display (CLD)## Ajustar 'Letters = letters' ou 'Letters = LETTERS' para minúsculas ou maiúsculas## Ajustar decreasing = TRUE para letras decrescentes e decreasing = FALSE para crescentestk_germinacao$emmeans |> multcomp::cld(Letters = letters, decreasing =TRUE)
tratamento emmean SE df asymp.LCL asymp.UCL .group
T3 1,572 0,168 Inf 1,2430 1,900 a
T2 1,109 0,146 Inf 0,8223 1,396 a
T1 0,323 0,128 Inf 0,0716 0,574 b
Controle -0,558 0,131 Inf -0,8157 -0,300 c
Results are given on the logit (not the response) scale.
Confidence level used: 0,95
Results are given on the log odds ratio (not the response) scale.
P value adjustment: tukey method for comparing a family of 4 estimates
significance level used: alpha = 0,05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
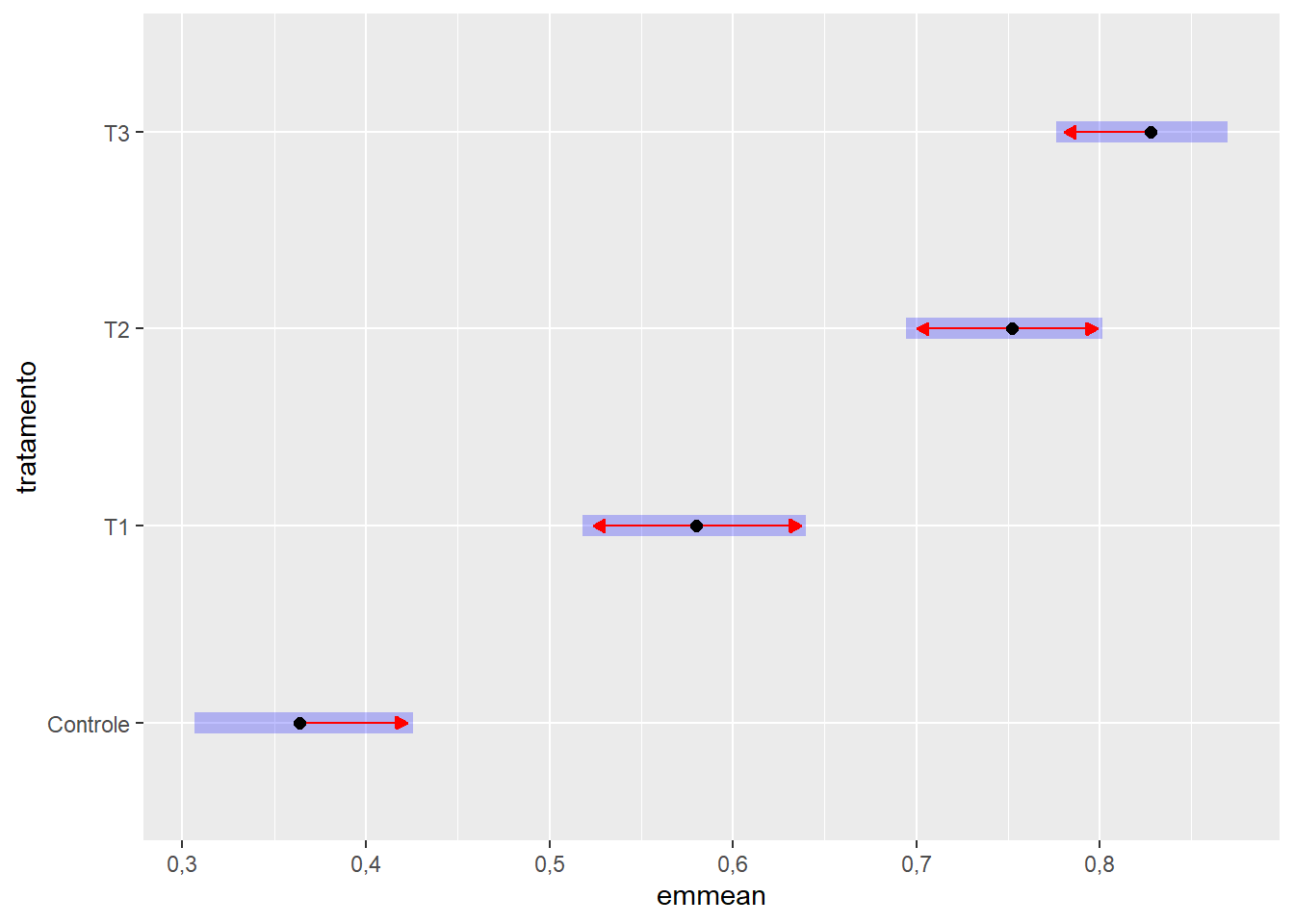
tk_germinacao$emmeans |> multcomp::cld(Letters = letters, decreasing =TRUE, type ="response")
tratamento prob SE df asymp.LCL asymp.UCL .group
T3 0,828 0,0239 Inf 0,776 0,870 a
T2 0,752 0,0273 Inf 0,695 0,802 a
T1 0,580 0,0312 Inf 0,518 0,640 b
Controle 0,364 0,0304 Inf 0,307 0,425 c
Confidence level used: 0,95
Intervals are back-transformed from the logit scale
P value adjustment: tukey method for comparing a family of 4 estimates
Tests are performed on the log odds ratio scale
significance level used: alpha = 0,05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
# Gráfico das médias com intervalo de confiançatk_germinacao$emmeans |>plot(comparisons =TRUE, CIs =TRUE, type ="response")